- MT5 Pro Set Incl. دیسک های ترمز طوفان HC - نسخه ویژه
- سرمایه گذاری کمی: هزینه معامله و تجزیه و تحلیل لغزش
- مطالعه روش جدید در زمان واقعی را برای شناسایی حباب های سهام مانند GameStop نشان می دهد
- بازار سهام امروز: سهام آسیایی عمدتاً به دلیل نگرانی نسبت به بانک های آمریکایی ، رشد چین کمتر است
- Cryptocurrency News - چگونه می توان لیست های سکه آینده را پیدا کرد؟
- بهترین 7 راه درآمد برای کسب درآمد از اینترنت بدون سرمایه گذاری
- باناریوم محدود
- 7 اصل برنامه ریزی استادانه
- تنظیم کننده سابق شهر می گوید ، هنگ کنگ به عنوان قوانین دارایی دیجیتال برای چین قوانین ماسهبازی برای چین است
- همه سزاوار داروهای ایمن و مقرون به صرفه هستند.

آخرین مطالب
امکانات وب



سریال های زمانی فرصتی برای پیش بینی ارزشهای آینده فراهم می کند. بر اساس مقادیر قبلی ، می توان از سری زمانی برای پیش بینی روندهای اقتصاد ، آب و هوا و برنامه ریزی ظرفیت استفاده کرد تا چند مورد را نامگذاری کند. خصوصیات خاص داده های سری زمانی به این معنی است که معمولاً روشهای آماری تخصصی مورد نیاز است.
در این آموزش ، ما هدف ما تولید پیش بینی های قابل اعتماد از سری های زمانی خواهیم بود. ما با معرفی و بحث در مورد مفاهیم همبستگی ، ثابت بودن و فصلی شروع خواهیم کرد و به کارگیری یکی از متداول ترین روش برای پیش بینی سری زمانی ، معروف به ARIMA می پردازیم.
یکی از روشهای موجود در پایتون برای مدل سازی و پیش بینی نقاط آینده یک سری زمانی به عنوان Sarimax شناخته می شود ، که مخفف میانگین های متحرک یکپارچه اتورگرایی فصلی با رگرسیون های اگزوژن است. در اینجا ، ما در درجه اول روی مؤلفه ARIMA تمرکز خواهیم کرد ، که برای متناسب بودن داده های سری زمانی برای درک بهتر و پیش بینی نقاط آینده در سری های زمانی استفاده می شود.
پیش نیازها
این راهنما نحوه انجام تجزیه و تحلیل سری زمانی را در یک دسک تاپ محلی یا یک سرور از راه دور پوشش می دهد. کار با مجموعه داده های بزرگ می تواند حافظه فشرده باشد ، بنابراین در هر صورت ، رایانه برای انجام برخی از محاسبات در این راهنما حداقل به 2 گیگابایت حافظه نیاز دارد.
برای استفاده بیشتر از این آموزش ، برخی از آشنایی با سری های زمانی و آمار می تواند مفید باشد.
برای این آموزش ، ما از نوت بوک Jupyter برای کار با داده ها استفاده خواهیم کرد. اگر قبلاً آن را ندارید ، باید آموزش ما را برای نصب و تنظیم نوت بوک Jupyter برای Python 3 دنبال کنید.
مرحله 1 - نصب بسته ها
برای تنظیم محیط ما برای پیش بینی سری زمانی ، اجازه دهید ابتدا به محیط برنامه نویسی محلی یا محیط برنامه نویسی مبتنی بر سرور خود حرکت کنیم:
از اینجا ، اجازه دهید یک دایرکتوری جدید برای پروژه ما ایجاد کنیم. ما آن را Arima خواهیم نامید و سپس به سمت فهرست حرکت خواهیم کرد. اگر پروژه را با نام دیگری فراخوانی می کنید ، حتماً نام خود را برای Arima در طول راهنما جایگزین کنید
این آموزش به کتابخانه های هشدارها ، Itertools ، Pandas ، Numpy ، Matplotlib و Statsmodels نیاز دارد. کتابخانه های هشدارها و IterTools با مجموعه استاندارد کتابخانه پایتون گنجانده شده است ، بنابراین نیازی به نصب آنها نیست.
مانند سایر بسته های پایتون ، می توانیم این الزامات را با PIP نصب کنیم. اکنون می توانیم پاندا ، statsmodels و بسته بندی نقشه نقشه برداری Matplotlib را نصب کنیم. وابستگی آنها نیز نصب خواهد شد:
در این مرحله ، ما اکنون تنظیم شده ایم تا با بسته های نصب شده کار کنیم.
مرحله 2 - وارد کردن بسته ها و بارگیری داده ها
برای شروع کار با داده های خود ، ما نوت بوک Jupyter را راه اندازی خواهیم کرد:
To create a new notebook file, select New>پایتون 3 از منوی کشویی بالا سمت راست:
این یک نوت بوک باز می شود.
همانطور که بهترین عمل است ، با وارد کردن کتابخانه هایی که در بالای نوت بوک خود نیاز دارید شروع کنید:
ما همچنین برای توطئه های خود یک سبک Matplotlib از Fivethirtyeight را تعریف کرده ایم.
ما با یک مجموعه داده به نام "CO2 جوی از نمونه های هوای مداوم در رصدخانه Mauna Loa ، هاوایی ، ایالات متحده" کار خواهیم کرد که نمونه های CO2 را از مارس 1958 تا دسامبر 2001 جمع آوری کرده است. ما می توانیم این داده ها را به شرح زیر بیاوریم:
بیایید قبل از حرکت به جلو ، داده های خود را کمی پردازش کنیم. داده های هفتگی می توانند کار با آنها مشکل باشند زیرا این یک زمان کوتاه تر است ، بنابراین اجازه دهید به جای آن از میانگین ماهانه استفاده کنیم. ما با عملکرد Resample تبدیل را تبدیل خواهیم کرد. برای سادگی ، ما همچنین می توانیم از عملکرد Fillna () استفاده کنیم تا اطمینان حاصل کنیم که در سری زمانی خود مقادیر از دست رفته نداریم.
بیایید این سری TIME E را به عنوان یک تجسم داده کشف کنیم:
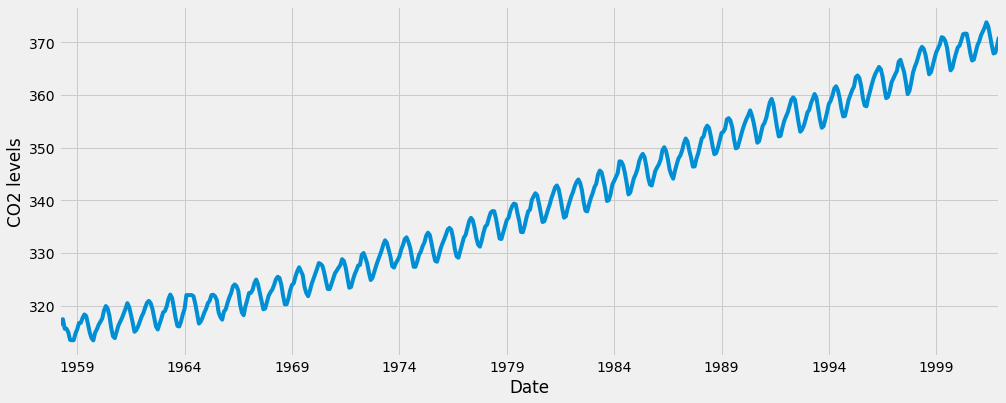
برخی از الگوهای قابل تشخیص هنگام ترسیم داده ها ظاهر می شوند. سریال های زمانی دارای یک الگوی فصلی آشکار و همچنین یک روند کلی فزاینده است.
برای کسب اطلاعات بیشتر در مورد پیش پردازش سری زمانی ، لطفاً به "راهنمای تجسم سری زمانی با Python 3" مراجعه کنید ، جایی که مراحل فوق با جزئیات بسیار بیشتری توضیح داده شده است.
اکنون که داده های خود را تبدیل کرده و کاوش کرده ایم ، بیایید به پیش بینی سریال های زمانی با Arima برویم.
مرحله 3 - مدل سری زمانی Arima
یکی از متداول ترین روشهای مورد استفاده در پیش بینی سری زمانی ، به عنوان مدل ARIMA شناخته می شود ، که مخفف یک uToreg r stogive i ntegrated m oving یک اصطلاح است. Arima مدلی است که می تواند برای درک بهتر یا پیش بینی نکات آینده در این سری ، در داده های سری زمانی قرار گیرد.
سه عدد صحیح مجزا (P ، D ، Q) وجود دارد که برای پارامتر کردن مدل های ARIMA استفاده می شود. به همین دلیل ، مدل های ARIMA با نماد Arima (P ، D ، Q) مشخص می شوند. این سه پارامتر با هم برای فصلی ، روند و سر و صدا در مجموعه داده ها به حساب می آیند:
- P بخش خودکار تگرگ مدل است. این امکان را به ما می دهد تا تأثیر مقادیر گذشته را در مدل خود بگنجانیم. به طور شهودی ، این امر شبیه به بیان اینكه احتمالاً اگر 3 روز گذشته گرم باشد ، احتمالاً فردا گرم خواهد بود.
- D قسمت یکپارچه مدل است. این شامل اصطلاحاتی در مدلی است که میزان تفاوت (یعنی تعداد نقاط زمان گذشته برای تفریق از مقدار فعلی) را در بر می گیرد تا در سری زمانی اعمال شود. به طور شهودی ، این می تواند شبیه به بیان این باشد که اگر اختلاف دما در سه روز گذشته بسیار اندک باشد ، احتمالاً فردا دما خواهد بود.
- q قسمت متوسط در حال حرکت مدل است. این به ما امکان می دهد خطای مدل خود را به عنوان ترکیبی خطی از مقادیر خطای مشاهده شده در نقاط زمانی قبلی در گذشته تنظیم کنیم.
هنگام برخورد با اثرات فصلی ، از Arima فصلی استفاده می کنیم ، که به عنوان Arima (P ، D ، Q) (P ، D ، Q) مشخص می شود. در اینجا ، (p ، d ، q) پارامترهای غیر فصلی است که در بالا توضیح داده شد ، در حالی که (p ، d ، q) از همان تعریف پیروی می کنند اما در مؤلفه فصلی سری زمانی اعمال می شوند. اصطلاح S دوره ای از سری زمانی است (4 برای دوره های سه ماهه ، 12 برای دوره های سالانه و غیره).
روش ARIMA فصلی به دلیل پارامترهای تنظیم چندگانه درگیر می تواند دلهره آور به نظر برسد. در بخش بعدی ، نحوه اتوماسیون فرایند شناسایی مجموعه بهینه پارامترها را برای مدل سری زمانی Arima فصلی توضیح خواهیم داد.
مرحله 4 - انتخاب پارامتر برای مدل سری زمانی Arima
هنگامی که به دنبال متناسب بودن داده های سری زمانی با یک مدل ARIMA فصلی هستیم ، اولین هدف ما یافتن مقادیر ARIMA (P ، D ، Q) (P ، D ، Q) است که یک معیار مورد علاقه را بهینه می کنند. دستورالعمل ها و بهترین روش ها برای دستیابی به این هدف وجود دارد ، اما پارامتر شدن صحیح مدل های ARIMA می تواند یک فرآیند دستی پر دردسر باشد که نیاز به تخصص و زمان دامنه دارد. سایر زبانهای برنامه نویسی آماری مانند R روشهای خودکار برای حل این مسئله را ارائه می دهند ، اما هنوز مواردی به پایتون منتقل نشده اند. در این بخش ، ما این مسئله را با نوشتن کد پایتون برای انتخاب برنامه نویسی مقادیر پارامتر بهینه برای مدل سری زمانی ARIMA (P ، D ، Q) (P ، D ، Q) حل خواهیم کرد.
ما از "جستجوی شبکه" استفاده خواهیم کرد تا به طور مکرر ترکیبات مختلف پارامترها را کشف کنیم. برای هر ترکیبی از پارامترها ، ما یک مدل جدید ARIMA فصلی را با عملکرد Sarimax () از ماژول Statsmodels قرار می دهیم و کیفیت کلی آن را ارزیابی می کنیم. هنگامی که ما کل چشم انداز پارامترها را کاوش کردیم ، مجموعه بهینه پارامترهای ما همان عملکردی خواهد بود که بهترین عملکرد را برای معیارهای مورد علاقه ما به دست می آورد. بیایید با تولید ترکیب مختلفی از پارامترهایی که می خواهیم ارزیابی کنیم شروع کنیم:
اکنون می توانیم از سه گانه پارامترهای تعریف شده در بالا برای خودکارسازی فرایند آموزش و ارزیابی مدل های ARIMA در ترکیب های مختلف استفاده کنیم. در آمار و یادگیری ماشین ، این فرایند به عنوان جستجوی شبکه (یا بهینه سازی هایپرپارامتر) برای انتخاب مدل شناخته می شود.
هنگام ارزیابی و مقایسه مدلهای آماری مجهز به پارامترهای مختلف ، هر یک را می توان بر اساس چگونگی مناسب بودن داده ها یا توانایی آن در پیش بینی دقیق نقاط داده های آینده در برابر یکدیگر قرار داد. ما از مقدار AIC (معیار اطلاعات Akaike) استفاده خواهیم کرد ، که به راحتی با مدل های ARIMA که با استفاده از statsmodels نصب شده است ، بازگردانده می شود. AIC اندازه گیری می کند که یک مدل در ضمن در نظر گرفتن پیچیدگی کلی مدل ، داده ها را متناسب می کند. مدلی که در هنگام استفاده از بسیاری از ویژگی ها ، داده ها را به خوبی متناسب می کند ، نمره AIC بزرگتر از مدلی اختصاص می یابد که از ویژگی های کمتری برای دستیابی به همان حسن نیت استفاده می کند. بنابراین ، ما علاقه مند به یافتن مدلی هستیم که کمترین مقدار AIC را به دست می آورد.
قطعه کد زیر از طریق ترکیب پارامترها تکرار می شود و از عملکرد Sarimax از statsmodels برای متناسب با مدل Arima فصلی مربوطه استفاده می کند. در اینجا ، آرگومان سفارش پارامترهای (P ، D ، Q) را مشخص می کند ، در حالی که آرگومان Seasonal_order مؤلفه فصلی (P ، D ، Q ، S) مدل ARIMA فصلی را مشخص می کند. پس از قرار دادن هر مدل Sarimax () ، کد نمره AIC مربوطه را چاپ می کند.
از آنجا که برخی از ترکیبات پارامترها ممکن است به اشتباهات عددی منجر شود ، ما به صراحت پیام های هشدار دهنده را غیرفعال می کنیم تا از اضافه بار پیام های هشدار دهنده جلوگیری کنیم. این اشتباهات همچنین می تواند منجر به خطاها و استثناء شود ، بنابراین ما اطمینان حاصل می کنیم که این استثناء را می گیریم و ترکیبات پارامتر را که باعث این مسائل می شود ، نادیده می گیریم.
کد فوق باید نتایج زیر را به دست آورد ، این ممکن است مدتی طول بکشد:
خروجی کد ما نشان می دهد که Sarimax (1 ، 1 ، 1) x (1 ، 1 ، 1 ، 12) کمترین مقدار AIC 277. 78 را به همراه دارد. بنابراین ما باید این گزینه را بهینه از بین تمام مدلهایی که در نظر گرفته ایم ، در نظر بگیریم.
مرحله 5 - متناسب با یک مدل سری زمانی Arima
با استفاده از جستجوی شبکه ، ما مجموعه ای از پارامترهایی را که بهترین مدل متناسب با داده های سری زمانی ما را تولید می کند ، شناسایی کرده ایم. ما می توانیم با عمق بیشتری به تجزیه و تحلیل این مدل خاص بپردازیم.
ما با وصل کردن مقادیر پارامتر بهینه به یک مدل جدید Sarimax شروع خواهیم کرد:
The summary attribute that results from the output of SARIMAX retus a significant amount of information, but we’ll focus our attention on the table of coefficients. The coef column shows the weight (i.e. importance) of each feature and how each one impacts the time series. The P>| Z |ستون ما را از اهمیت هر وزن ویژگی مطلع می کند. در اینجا ، هر وزن دارای مقدار p پایین تر یا نزدیک به 0. 05 است ، بنابراین حفظ همه آنها در مدل ما منطقی است.
هنگام قرار دادن مدلهای ARIMA فصلی (و هر مدل دیگری برای آن موضوع) ، مهم است که تشخیص مدل را اجرا کنید تا اطمینان حاصل شود که هیچ یک از فرضیات ساخته شده توسط مدل نقض نشده است. شیء plot_diagnostics به ما امکان می دهد تا به سرعت تشخیص مدل را تولید کنیم و هرگونه رفتار غیرمعمول را بررسی کنیم.
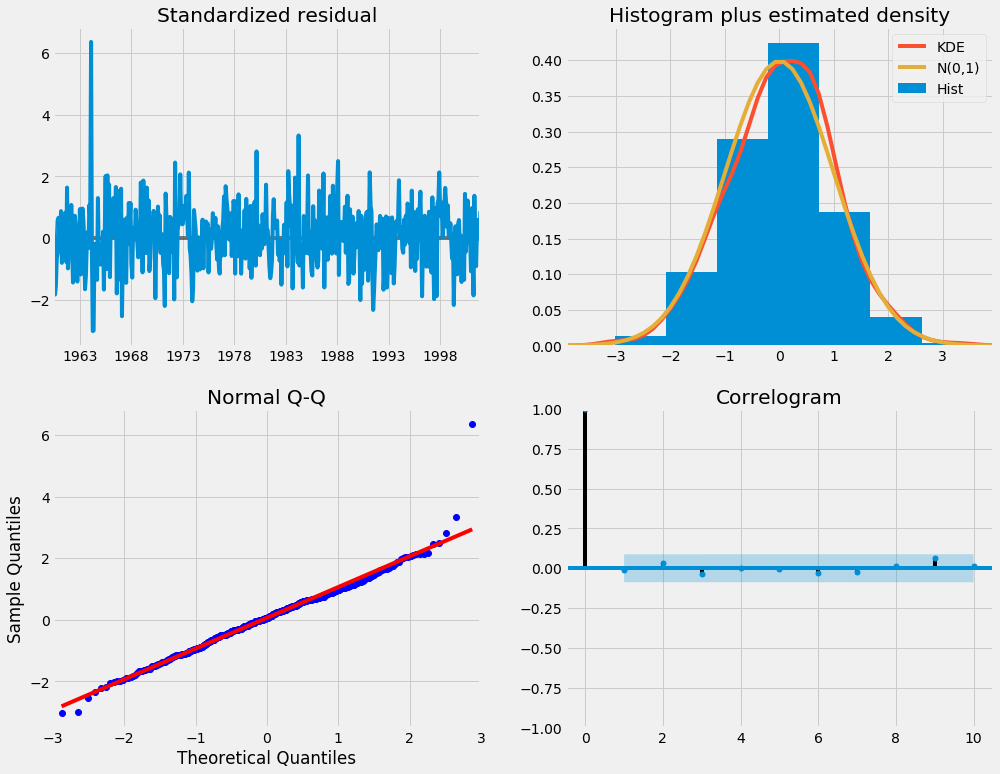
نگرانی اصلی ما این است که اطمینان حاصل کنیم که باقیمانده های مدل ما با هم مرتبط نیستند و به طور معمول با میانگین صفر توزیع می شوند. اگر مدل ARIMA فصلی این خصوصیات را برآورده نکند ، این یک نشانه خوب است که می توان آن را بیشتر بهبود بخشید.
در این حالت ، تشخیص مدل ما نشان می دهد که باقیمانده های مدل به طور معمول بر اساس موارد زیر توزیع می شوند:
در طرح بالا سمت راست ، می بینیم که خط قرمز KDE از نزدیک با خط N (0،1) (جایی که n (0،1)) از نزدیک دنبال می شود ، نماد استاندارد برای توزیع عادی با میانگین 0 و انحراف استاندارد 1 است)بشراین یک نشانه خوب است که باقیمانده ها به طور معمول توزیع می شوند.
قطعه QQ در پایین سمت چپ نشان می دهد که توزیع سفارش داده شده باقیمانده (نقاط آبی) روند خطی نمونه های گرفته شده از یک توزیع عادی استاندارد با N (0 ، 1) را دنبال می کند. باز هم ، این یک نشانه قوی است که باقیمانده ها به طور معمول توزیع می شوند.
باقیمانده ها به مرور زمان (طرح بالا سمت چپ) هیچ فصلی آشکار را نشان نمی دهند و به نظر می رسد سر و صدای سفید است. این با طرح همبستگی (یعنی همبستگی) در پایین سمت راست تأیید می شود ، که نشان می دهد باقیمانده های سری زمانی با نسخه های تاخیر از خود ارتباط کم دارند.
این مشاهدات ما را به این نتیجه می رساند که مدل ما تناسب رضایت بخش تولید می کند که می تواند به ما در درک داده های سری زمانی و پیش بینی ارزش های آینده کمک کند.
اگرچه ما از تناسب رضایت بخش برخوردار هستیم ، برخی از پارامترهای مدل ARIMA فصلی ما می توانند برای بهبود تناسب مدل ما تغییر کنند. به عنوان مثال ، جستجوی شبکه ما فقط مجموعه ای محدود از ترکیب پارامترها را در نظر گرفته است ، بنابراین اگر جستجوی شبکه را گسترش دهیم ممکن است مدل های بهتری پیدا کنیم.
مرحله 6 - اعتبارسنجی پیش بینی ها
ما مدلی را برای سری زمانی خود بدست آورده ایم که هم اکنون می تواند برای تولید پیش بینی ها استفاده شود. ما با مقایسه مقادیر پیش بینی شده با مقادیر واقعی سری زمان شروع می کنیم ، که به ما کمک می کند تا صحت پیش بینی های خود را درک کنیم. ویژگی های get_prediction () و conf_int () به ما امکان می دهد مقادیر و فواصل اطمینان مرتبط را برای پیش بینی های سری زمانی بدست آوریم.
کد فوق نیاز به پیش بینی ها در ژانویه 1998 دارد.
استدلال پویا = نادرست تضمین می کند که ما پیش بینی های یک مرحله ای را پیش بینی می کنیم ، به این معنی که پیش بینی در هر نقطه با استفاده از تاریخچه کامل تا آن نقطه تولید می شود.
ما می توانیم مقادیر واقعی و پیش بینی شده سری زمان CO2 را ترسیم کنیم تا ارزیابی کنیم که چقدر خوب انجام دادیم. توجه کنید که چگونه با برش فهرست تاریخ ، در پایان سری زمانی بزرگنمایی کردیم.
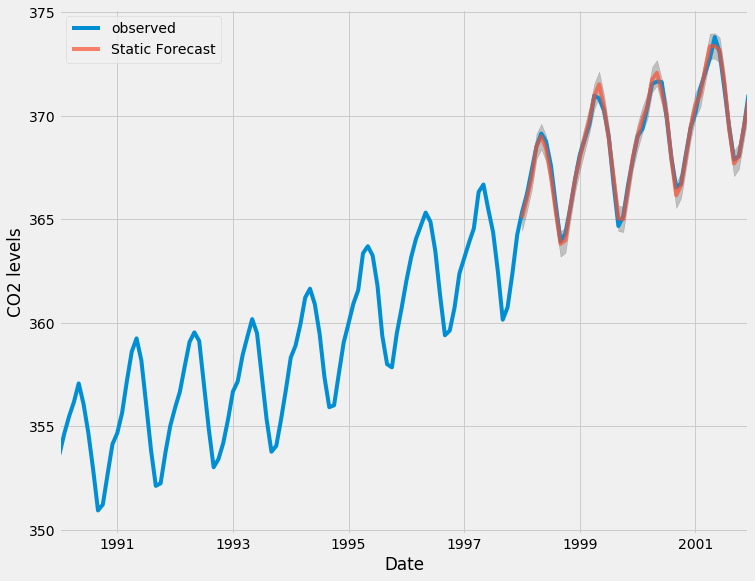
به طور کلی ، پیش بینی های ما با مقادیر واقعی بسیار خوب مطابقت دارد و روند افزایش کلی را نشان می دهد.
همچنین تعیین دقت پیش بینی های ما مفید است. ما از MSE (میانگین خطای مربع) استفاده خواهیم کرد ، که خلاصه خطای متوسط پیش بینی های ما است. برای هر مقدار پیش بینی شده ، فاصله آن را به مقدار واقعی محاسبه می کنیم و نتیجه را مربع می کنیم. نتایج باید به صورت مربع باشد تا وقتی که میانگین کلی را محاسبه می کنیم ، اختلافات مثبت/منفی یکدیگر را لغو نکند.
MSE پیش بینی های یک مرحله ای پیش رو ما مقدار 0. 07 را به دست می آورد ، که بسیار کم است زیرا نزدیک به 0 است. MSE از 0 که این برآوردگر در حال پیش بینی مشاهدات پارامتر با دقت کامل است ، که می تواند یک سناریوی ایده آل باشداما به طور معمول امکان پذیر نیست.
با این حال ، بازنمایی بهتری از قدرت پیش بینی واقعی ما می تواند با استفاده از پیش بینی های پویا بدست آید. در این حالت ، ما فقط از اطلاعات سری زمانی تا یک نقطه خاص استفاده می کنیم و پس از آن ، پیش بینی ها با استفاده از مقادیر از نقاط زمانی پیش بینی شده قبلی تولید می شوند.
در بخش کد زیر ، ما مشخص می کنیم که محاسبه پیش بینی های پویا و فواصل اطمینان را از ژانویه 1998 به بعد شروع کنیم.
با ترسیم مقادیر مشاهده شده و پیش بینی شده از سری زمانی ، می بینیم که پیش بینی های کلی حتی هنگام استفاده از پیش بینی های پویا دقیق هستند. تمام مقادیر پیش بینی شده (خط قرمز) تقریباً با حقیقت زمین (خط آبی) مطابقت دارند و در فواصل اطمینان پیش بینی ما هستند.
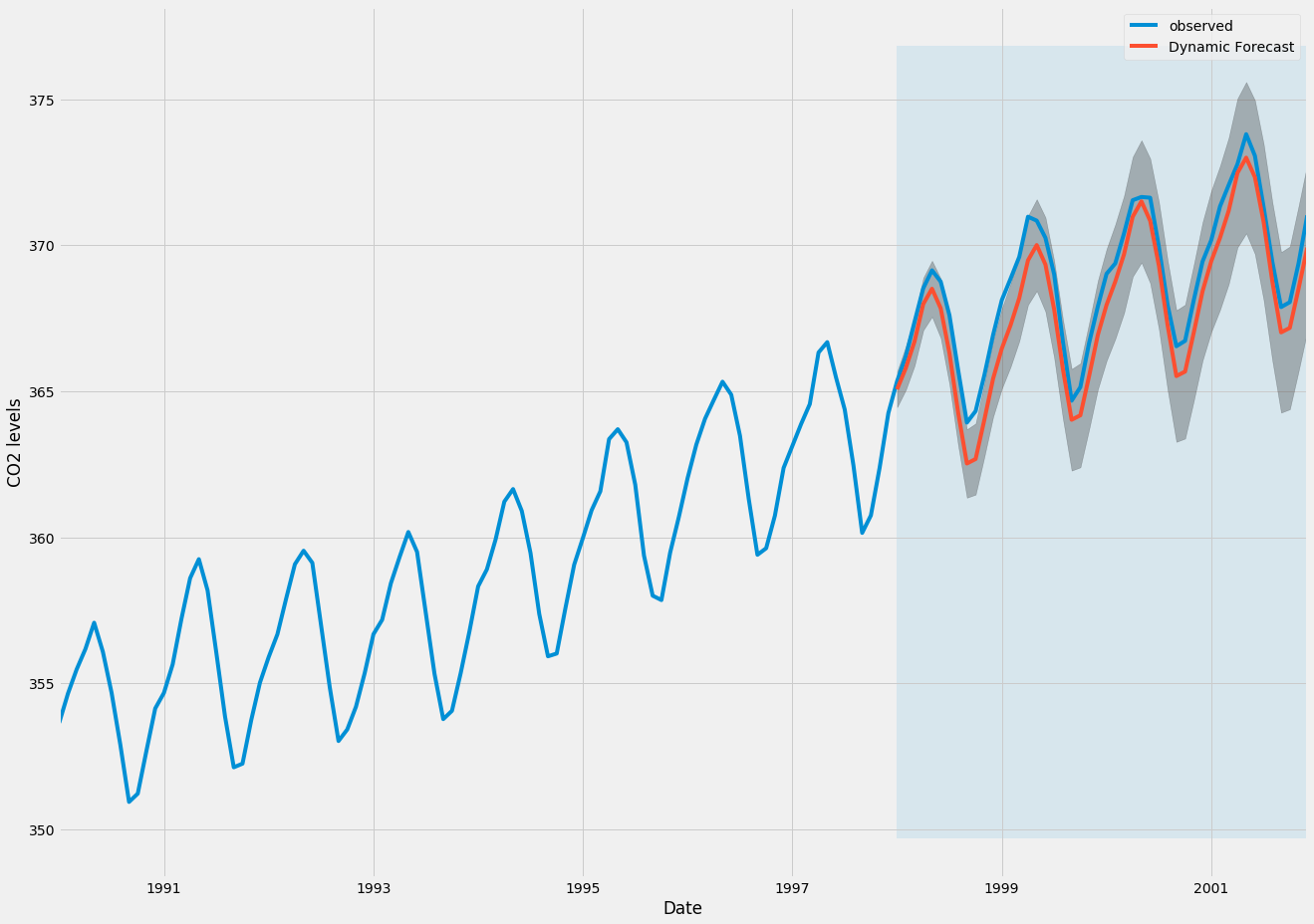
یک بار دیگر ، ما عملکرد پیش بینی پیش بینی های خود را با محاسبه MSE تعیین می کنیم:
مقادیر پیش بینی شده به دست آمده از پیش بینی های پویا MSE 1. 01 را به همراه دارد. این کمی بالاتر از یک مرحله پیش رو است ، که انتظار می رود با توجه به اینکه ما از سری زمانی به داده های تاریخی کمتری تکیه می کنیم.
پیش بینی های یک مرحله ای جلوتر و پویا تأیید می کنند که این مدل سری زمانی معتبر است. با این حال ، بسیاری از علاقه های مربوط به پیش بینی سریال های زمانی ، توانایی پیش بینی ارزش های آینده به موقع است.
مرحله 7 - تولید و تجسم پیش بینی ها
در مرحله پایانی این آموزش ، ما توضیح می دهیم که چگونه می توان از مدل سری زمانی آریما خود برای پیش بینی مقادیر آینده استفاده کرد. ویژگی get_forecast () از شیء سری زمانی ما می تواند مقادیر پیش بینی شده را برای تعداد مشخصی از مراحل پیش رو محاسبه کند.
ما می توانیم از خروجی این کد برای ترسیم سری زمان و پیش بینی مقادیر آینده آن استفاده کنیم.
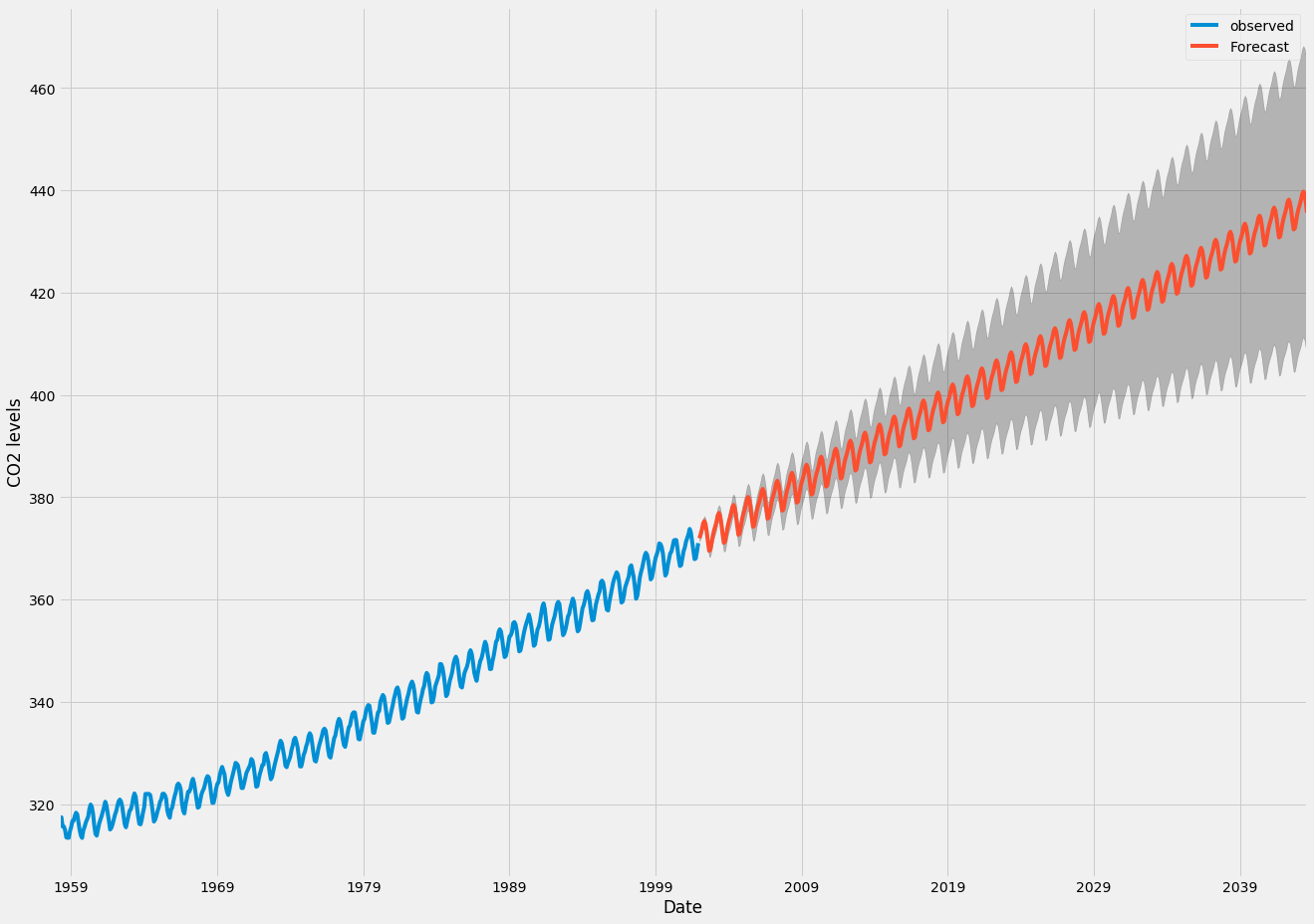
هم پیش بینی ها و هم فاصله اطمینان مرتبط با آن که ما تولید کرده ایم می توان برای درک بیشتر سری زمانی و پیش بینی آنچه انتظار دارد استفاده کرد. پیش بینی های ما نشان می دهد که انتظار می رود سری زمانی با سرعت ثابت در حال افزایش باشد.
همانطور که پیش بینی می کنیم بیشتر به آینده بپردازیم ، برای ما طبیعی است که به ارزشهای خود اعتماد به نفس کمتری داشته باشیم. این با فواصل اطمینان حاصل از مدل ما منعکس می شود ، که با افزایش بیشتر به آینده ، بزرگتر می شویم.
نتیجه
در این آموزش ، ما نحوه اجرای یک مدل ARIMA فصلی در پایتون را توضیح دادیم. ما از کتابخانه های پاندا و statsmodels استفاده گسترده ای کردیم و نشان دادیم که چگونه می توان تشخیص مدل را اجرا کرد ، و همچنین نحوه تولید پیش بینی های سری زمانی CO2.
در اینجا چند مورد دیگر وجود دارد که می توانید امتحان کنید:
- تاریخ شروع پیش بینی های پویا خود را تغییر دهید تا ببینید که چگونه این بر کیفیت کلی پیش بینی های شما تأثیر می گذارد.
- ترکیبات بیشتری از پارامترها را امتحان کنید تا ببینید که آیا می توانید خوب بودن مدل خود را بهبود بخشید.
- برای انتخاب بهترین مدل یک متریک متفاوت را انتخاب کنید. به عنوان مثال ، ما از اندازه گیری AIC برای یافتن بهترین مدل استفاده کردیم ، اما به جای آن می توانید به دنبال بهینه سازی خطای میانگین مربع خارج از نمونه باشید.
برای تمرین بیشتر ، همچنین می توانید سعی کنید مجموعه داده های سری زمانی دیگری را برای تولید پیش بینی های خود بارگیری کنید.
اگر از این آموزش و جامعه گسترده تر ما لذت بردید ، در نظر بگیرید که محصولات دیجیتالی ما را بررسی کنید که می تواند به شما در دستیابی به اهداف توسعه خود نیز کمک کند.
سری آموزش: تجسم و پیش بینی سری زمانی
سری زمانی یک مؤلفه مهم تجزیه و تحلیل داده ها است. این سریال نحوه رسیدگی به تجسم و پیش بینی سری زمانی در پایتون 3 را انجام می دهد.
استراتژی ترید...
ما را در سایت استراتژی ترید دنبال می کنید
برچسب :
نویسنده : مرجان شیرمحمدی
بازدید : 97
