- MT5 Pro Set Incl. دیسک های ترمز طوفان HC - نسخه ویژه
- سرمایه گذاری کمی: هزینه معامله و تجزیه و تحلیل لغزش
- مطالعه روش جدید در زمان واقعی را برای شناسایی حباب های سهام مانند GameStop نشان می دهد
- بازار سهام امروز: سهام آسیایی عمدتاً به دلیل نگرانی نسبت به بانک های آمریکایی ، رشد چین کمتر است
- Cryptocurrency News - چگونه می توان لیست های سکه آینده را پیدا کرد؟
- بهترین 7 راه درآمد برای کسب درآمد از اینترنت بدون سرمایه گذاری
- باناریوم محدود
- 7 اصل برنامه ریزی استادانه
- تنظیم کننده سابق شهر می گوید ، هنگ کنگ به عنوان قوانین دارایی دیجیتال برای چین قوانین ماسهبازی برای چین است
- همه سزاوار داروهای ایمن و مقرون به صرفه هستند.

آخرین مطالب
امکانات وب


ما به تازگی با یک شریک خدمات مالی همکاری کرده ایم تا الگویی را برای پیش بینی عملکرد آینده بورس سهام شرکتهای دولتی در دسته هایی که در آن سرمایه گذاری می کنند ، تهیه کنیم. هدف استفاده از بخش های روایت متن از اسناد منتشر شده درآمدهای عمومی برای پیش بینی و هشدار دادن تحلیلگران خود در مورد فرصت ها و خطرات سرمایه گذاری بود. ما یک مدل یادگیری عمیق را با استفاده از یک شبکه عصبی یک بعدی (یک CNN 1D) بر اساس متن استخراج شده از صورتهای مالی عمومی از این شرکت ها برای انجام این پیش بینی ها تهیه کردیم. ما از Azure Machine Leaing Workbench برای کشف داده ها و توسعه مدل استفاده کردیم. ما راه حل خود را با استفاده از چارچوب Python Leaing Deep Deep Leaing با یک پس زمینه Theano مدل کردیم. نتایج ما نشان می دهد که چگونه یک مدل یادگیری عمیق که در متن در نسخه های درآمد آموزش داده شده است و منابع دیگر می توانند سیگنال ارزشمندی را برای یک تصمیم گیرنده سرمایه گذاری فراهم کنند.
چالش
هنگام بررسی تصمیمات سرمایه گذاری ، یک شرکت باید از تمام اطلاعات ممکن استفاده کند و از اسناد در دسترس عموم مانند گزارش های 10-K استفاده می کند. با این حال ، بررسی اسناد انتشار درآمدهای عمومی زمان بسیار زیاد است و تجزیه و تحلیل حاصل می تواند ذهنی باشد. علاوه بر این ، بخش های نوشتاری از انتشار درآمد بیشترین زمان را به بررسی نیاز دارند و اغلب ذهنی ترین تفسیر هستند. تجزیه و تحلیل کامل از فرصت سرمایه گذاری یک تجارت همچنین شامل بررسی سایر شرکت ها در صنعت برای درک عملکرد نسبی است. چالش ما ساختن یک الگوی پیش بینی کننده بود که می تواند یک بررسی اولیه از این اسناد را به طور مداوم و اقتصادی انجام دهد و به تحلیلگران سرمایه گذاری اجازه می دهد تا زمان تجزیه و تحلیل پیگیری خود را با کارآمدتر متمرکز کنند و منجر به تصمیمات سرمایه گذاری بهتری شوند.
برای این پروژه ، ما به دنبال نمونه ای از یک مدل پیش بینی کننده برای ارائه قضاوت های مداوم در مورد چشم انداز آینده یک شرکت ، بر اساس بخش های متنی نوشتاری از انتشار درآمد عمومی استخراج شده از نسخه های 10K و عملکرد واقعی بورس بودیم. ما از پردازش زبان طبیعی (NLP) پیش پردازش و یادگیری عمیق در برابر این متن منبع استفاده کردیم. در پایان ، ما به دنبال مدلی بودیم که به مرور زمان عملیاتی کردن ، استفاده و حفظ آن آسان بود. در حالی که کاربردهای بالقوه تری برای پردازش روایت های انتشار درآمدهای عمومی برای پیش بینی ارزش سهام آینده وجود دارد ، برای اهداف این پروژه ، ما فقط بر روی تولید پیش بینی هایی متمرکز شده ایم که می تواند بهتر از تجزیه و تحلیل انسانی بیشتر توسط شریک زندگی ما آگاه شود.
رویکرد ما
ابزار ، پیش پردازش و اکتشافات اولیه NLP
ما کار خود را در پایتون با Azure Machine Leaing Workbench شروع کردیم و داده های خود را با کمک نوت بوک یکپارچه Jupyter بررسی کردیم. ما از کتابخانه های پایه AML Workbench Python ، از جمله NLTK استفاده کردیم و برخی از بسته های اضافی و ابزارهای NLP از جمله کتابخانه Gensim را اضافه کردیم. کلیه اسکریپت ها و داده های نمونه در این repo github ، از جمله نوت بوک های Jupyter برای هر یک از مراحل ، از فیلتر کردن داده های منبع گرفته تا پیش پردازش ، اجرای و ارزیابی مدل موجود است. برای آسانتر کردن کارها ، لیستی از بسته ها و برنامه های پایتون را برای نصب در بالای پایه کارگروه یادگیری ماشین Azure Leaing Python که در README ذکر شده است ، پیدا خواهید کرد.
به عنوان ورودی ، ما یک متن متنی از دو سال اطلاعات انتشار برای هزاران شرکت دولتی در سراسر جهان جمع آوری کردیم. ما به عنوان منبع بخش های 1 ، 1A ، 7 و 7A از 10K هر شرکت استخراج کردیم - بحث در مورد تجارت ، نمای کلی مدیریت و افشای خطرات و خطرات بازار. ما همچنین در روز انتشار درآمد و قیمت سهام چهار هفته بعد ، قیمت سهام هر یک از شرکت ها را جمع کردیم. ما شرکت های دولتی را بر اساس گروه صنعت طبقه بندی کردیم.
ما متن را از قبل پردازش کردیم ، به UTF-8 تبدیل شدیم و نگارشی را از بین بردیم ، کلمات را متوقف کنیم و هر رشته شخصیت کمتر از 2 کاراکتر. نوت بوک های پیش پردازش Jupyter در GitHub (فیلتر متن منبع و تمیز کردن متن) قرار دارند. بسیاری از تکنیک هایی که ما استفاده کردیم به تفصیل در NLTK در کتاب پایتون شرح داده شده است. در زیر نمونه ای از متن تمیز شده است که در این حالت نمونه ای از یک مرور کلی مدیریت از انتشار یک درآمد است. تعدادی از نمونه های اسناد متنی در GitHub موجود است.
نکته مهم در رویکرد ما نمونه محدود داده ما با کمتر از 35000 نمونه اسناد متنی فردی در صنایع بود که اندازه نمونه بسیار کمتری در یک صنعت داشت. در بیوتکنولوژی ، ما 943 نمونه سند متن داشتیم. در نتیجه محدودیت های نمونه ، نتایج پروژه ما باید به سادگی اثبات مفهوم مورد تأیید و بهبود با نمونه های اضافی باشد.
عامل دیگر مقادیر زیادی واژگان خاص صنعت موجود در هر یک از اسناد متنی بود. برای درک بهتر تنوع موجود در جسد ، متن را به کمک روشها و کتابخانه های NLP از جمله NLTK و GENSIM تمیز کردیم. هنگام بازرسی از متن منبع از نسخه های شرکت های عمومی با تجزیه و تحلیل مدل موضوع LDA ، دریافتیم که مقدار زیادی از واژگان بین واژگان صنعت و تنوع بسیار کمتری در صنایع وجود دارد. این یافته باعث شد تا به منظور کاهش میزان سر و صدای تنوع کمتر معنی دار ، مدل طبقه بندی عملکرد خود را بر اساس صنایع منفرد و نه در سراسر آنها نمونه برداری کنیم. نوت بوک Jupyter جزئیات اکتشاف متن اولیه را در پوشه نوت بوک های Jupyter شرح می دهد.
نمایانگر اسناد به عنوان بردارهای کلمه ای
برای استفاده از یادگیری عمیق NLP ، ما نیاز به بازنمایی عددی برای متن خود داشتیم. به طور خاص ، ما برای هر یک از اسناد خود به نمایندگی بردار نیاز داشتیم. زبان طبیعی ، با توجه به ماهیت خود ، همبستگی های مکانی بین کلمات را بومی کرده است. به عنوان مثال ، اگر کلمه "آفتابی" را پیدا کردید ، ممکن است بیشتر از یک کلمه کمتر مرتبط با یک جمله "آب و هوا" را در همان جمله پیدا کنید. مدل های بردار کلمه این روابط را به صورت عددی نشان می دهند. به طور خاص ، تعبیه Word تکنیکی است که در آن جفت های کلمه می توانند بر اساس فاصله اقلیدسی بین آنها نشان داده شوند که می تواند تفاوت های معنایی و شباهت ها را رمزگذاری کند. این مسافت ها را می توان با تفاوت های بردار نشان داد.
دو گزینه برای ایجاد تعبیه کلمه وجود داشت. ما می توانیم بر اساس متن متن منبع ، تعبیه های سفارشی ایجاد کنیم ، یا می توانیم یک مدل از پیش آموزش داده شده را بر اساس یک متن بسیار بزرگتر از متن استفاده کنیم. با توجه به اندازه محدود نمونه ما ، ما به دنبال برداشت بردارهای کلمه ای از قبل آموزش دیده بودیم. در مورد ما ، از مدل های از پیش آموزش دستکش استفاده کردیم. این مدلهای از قبل آموزش دیده بر روی همزمان کل جهانی کلمه از انواع مجموعه داده های بسیار بزرگ آموزش داده شدند. نتیجه یک بردار است که نمایانگر زیر ساخت خطی فضای بردار کلمه است. ما از مدل از پیش آموزش دستکش از همه داده های 2014 ویکی پدیا ، یک مدل وکتور واژگان 400000 کلمه ای ، برای پوشش دامنه گسترده خود و ماهیت کمتر محاوره استفاده کردیم. این مجموعه از قبل آموزش دیده از بردارهای کلمه ای به ما این امکان را می دهد تا مجموعه اسناد خود را برداشت کنیم و آن را برای ابزارهای یادگیری عمیق آماده کنیم.
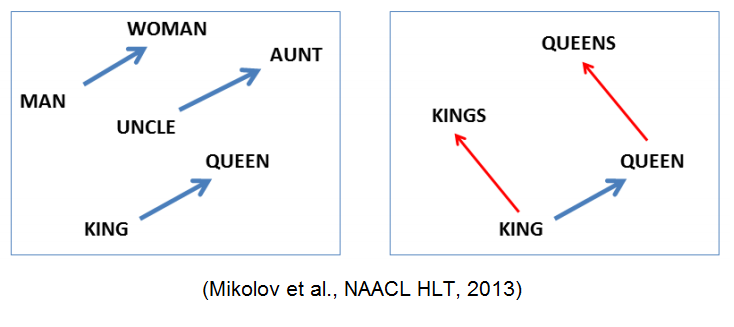
نمونه بردار کلمه
اگرچه این مدل از قبل آموزش دیده دارای واژگان گسترده 400000 کلمه ای است ، اما هنوز هم محدودیت هایی دارد زیرا مربوط به متن متن ما است. به عنوان مثال ، در صنایع مبتنی بر فناوری ، یک واژگان بسیار تخصصی و خاص دامنه وجود دارد که ممکن است در مدل کلمه از پیش آموزش داده نشود. این اصطلاحات واژگان ممکن است پیش بینی کننده عملکرد باشد ، اما وقتی از این مدل های کلمه از قبل آموزش داده شده استفاده کردیم ، کلمات خارج از فوکوس همه مقادیر بردار کلمه ای را دریافت می کنند که ارزش پیش بینی آنها را کاهش می دهد. برای برخی از صنایع ، این واژگان با گذشت زمان با توسعه فن آوری ها ، ترکیبات یا محصولات جدید تغییر می کنند. در نتیجه ، بردار کلمه این کلمات در حال تغییر ممکن است در دوره های مختلف متفاوت باشد. حضور جدیدترین واژگان فناوری نیز ممکن است دارای ارزش پیش بینی کننده باشد. علاوه بر این ، اظهارات انتشار درآمد شرکت ها با یک پاتوی ظریف خاص ارائه می شود که به طور کامل در مدل دستکش از قبل آموزش داده نشده در مقالات ویکی پدیا منعکس نشده است.
تحقیقات در مورد روشهای جدید برای مقابله با کلمات واژگان برای واژگان کوچک و بعد زمانی کلمات واژگان در حال ظهور است. این پست خلاصه ای از تحقیقات مهم NLP اخیر است که نوید می دهد این موضوعات را در آینده حل کند.
برچسب های طبقه بندی و هدف پیش بینی
ما بر اساس عملکرد سهام بین تاریخ انتشار و چهار هفته بعد، سه سطل طبقه بندی با اندازه یکسان با عملکرد بالا، متوسط و پایین ایجاد کردیم. عملکرد به عنوان درصد تغییر در ارزش سهام در آن زمان محاسبه شد و مقداری نرمال سازی برای تغییرات کلی بازار سهام اعمال شد. این دسته بندی های عملکرد کم، متوسط و بالا 4 هفته ای برچسب های مدل ما بودند. ما نمونه اولیه خود را فقط از یک صنعت، صنعت بیوتکنولوژی، که بیشترین نمونه درون صنعت را داشت، الگوبرداری کردیم. هدف پروژه ما تشخیص این بود که آیا می توانیم از دقت شانسی 33. 33% بهتر عمل کنیم.
مدل شبکه عصبی کانولوشنال با کراس
با اسناد ما که توسط یک سری جاسازی نشان داده شد، ما توانستیم از یک مدل شبکه عصبی کانولوشنال (CNN) برای یادگیری طبقه بندی ها استفاده کنیم. سی ان ان ها می توانند به خوبی برای مدل سازی اسناد مناسب باشند، زیرا می توانند ساختارهای نحوی کوچک (و سپس بزرگ) را در مجموعه آموزشی از طریق مراحل ادغام حداکثری و ادغام پیدا کنند و یک مدل کامل تر از پیکره منبع بسازند (درباره CNN با NLP بیشتر بخوانید). در زیر تصویری از یک CNN یک لایه است. با نمونه محدودی از اسناد منبع و بازه زمانی بسیار محدود نقاط داده ما، به جای استفاده از مدل LSTM برای این پروژه، CNN یک بعدی ساده تر را انتخاب کردیم.
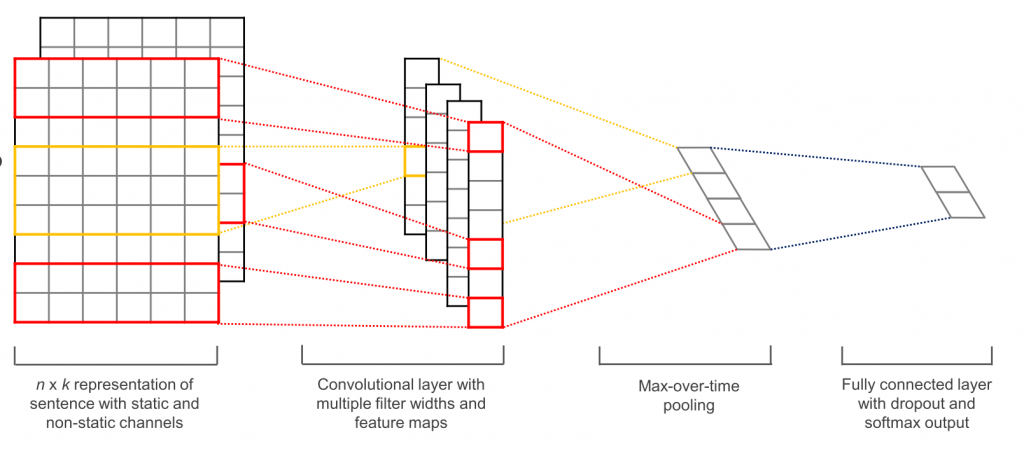
ما از یک CNN 1 بعدی در Keras با استفاده از جاسازی کلمات سفارشی خود استفاده کردیم. این نمونه عالی Keras را برای معماری 1 بعدی CNN با استفاده از جاسازی کلمات سفارشی، مانند بردارهای کلمه مدل Glove از پیش آموزش دیده، ببینید. در طراحی مدل خود، ما از مرجع Keras به عنوان پایگاه معماری خود شروع کردیم و از آنجا اصلاح کردیم.
ما یک دنباله 10000 کلمه ای را به عنوان حداکثر انتخاب کردیم. برای اسنادی با بیش از 10000 کلمه، متن باقی مانده را کوتاه کردیم. برای اسنادی با کمتر از 10000 کلمه، دنباله را در پایان با صفر اضافه کردیم. ما هر یک از کلمات خود را در هر دنباله به یکی از آیتم های واژگان جاسازی دستکش نگاشت کردیم و از نمایش عددی 300 مقدار آن استفاده کردیم. برای هر نمونه سند، ما یک نمایش توالی 10000 در 300 داشتیم. در زیر گزیده ای از ساخت ماتریس تعبیه شده از این اسکریپت است.
برای خود مدل ، ما از Adam Optimizer ، LeCun Initializer استفاده کردیم و از عملکرد فعال سازی واحد خطی ("ELU") استفاده کردیم. ما در تمرین (15 ٪ به لایه های داخلی و 45 ٪ به لایه نهایی) و ویژگی توقف زود هنگام Keras برای جلوگیری از تناسب بیش از حد استفاده کردیم. همچنین ، ما نرخ یادگیری را از مدل اولیه پایین آوردیم تا نتایج آزمون را به 0. 00011 بهبود بخشیم. ما فهمیدیم که این مدل نسبت به گزینه های اولیه ساز بسیار حساس است ، با مدل LECUN یادگیری بسیار بهتری نسبت به سایر سایر ابتکارات موجود در کروها ارائه می دهد. پس از آزمایش تمام گزینه های بهینه ساز در Keras ، دریافتیم که بهینه سازهای ADAM و RMSProp بسیار بهتر از سایر بهینه سازها عمل می کنند ، در حالی که آدام عملکرد کمی بهتر دارد. هنگامی که ما از عملکرد "ELU" استفاده کردیم ، این مدل کمتر از عملکردهای فعال سازی RELU ، PRELU یا LEAKY RELU کمرنگ تر است و به دقت بیشتری می رسید. برای بهبود یادگیری ، اندازه دسته ای را به اندازه متوسط 33 کاهش دادیم.
به منظور بهبود مدل ، ما داده ها را در متن اصلی با عنوان بخش از گزارش 10-K افزایش دادیم. ما این متن را به شروع نمونه سند اضافه کردیم. افزایش داده های مبتنی بر اصطلاحنامه در NLP در این بحث در مورد این انجمن در عمق بیشتری مورد بحث قرار می گیرد.
برخی از گزینه های Hyperparameter و معماری مدل در زیر شرح داده شده است. همچنین ، نوت بوک کامل Jupyter و این راهنمای عملی برای عیب یابی و تنظیم شبکه عصبی خود را ببینید.

نتیجه
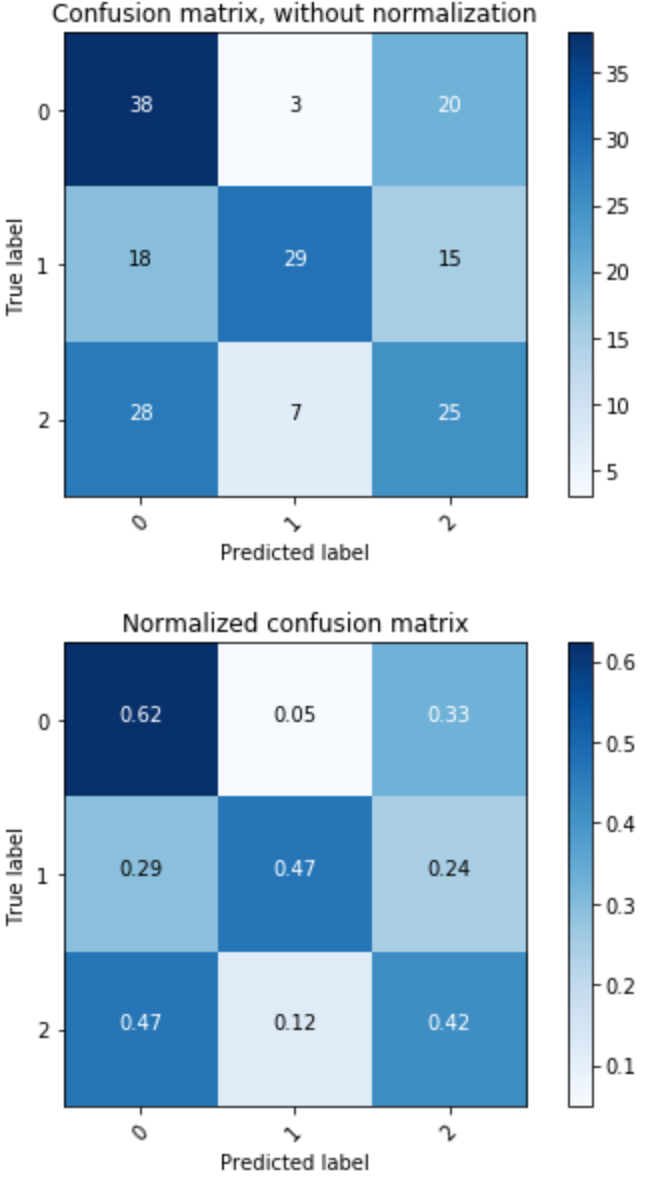
نتایج مدل نمونه اولیه ما ، در حالی که متوسط است ، نشان می دهد که یک سیگنال مفید در طبقه بندی عملکرد آینده حداقل در صنعت بیوتکنولوژی بر اساس متن هدف از 10-K وجود دارد. آمار حاصل در زیر ذکر شده است ، از جمله آمار توسط کلاس. برای مدل ما ، ‘0" عملکرد پایین را نشان می دهد ، ‘1" عملکرد متوسط را نشان می دهد و 2 ‘نشان دهنده عملکرد بالا است (به نوت بوک ارزیابی مدل مراجعه کنید).
ماتریس سردرگمی زیر پیش بینی مقایسه کلاس واقعی نمونه و کلاس پیش بینی شده را نشان می دهد. برچسب واقعی در محور عمودی است و برچسب پیش بینی شده از مدل ما در محور افقی است. شبکه بالا تعداد مطلق است و شبکه پایین درصد است. تجسم نشان می دهد که مدل ما در پیش بینی برچسب واقعی سهام کم عملکرد ، در سمت چپ فوقانی بهترین عملکرد را دارد.
برای شرکت های سرمایه گذاری ، پیش بینی کم عملکرد ممکن است با ارزش ترین پیش بینی همه باشد ، و به آنها امکان می دهد از زیان سرمایه گذاری هایی که به خوبی کرایه نمی کنند ، جلوگیری کنند. شانس می توانست برای هر طبقه بندی ، 33. 3 ٪ دقت به ما بدهد. در این مدل ، ما شاهد دقت 62 ٪ برای پیش بینی شرکت کم عملکرد بر اساس نمونه 10-K نمونه هستیم.
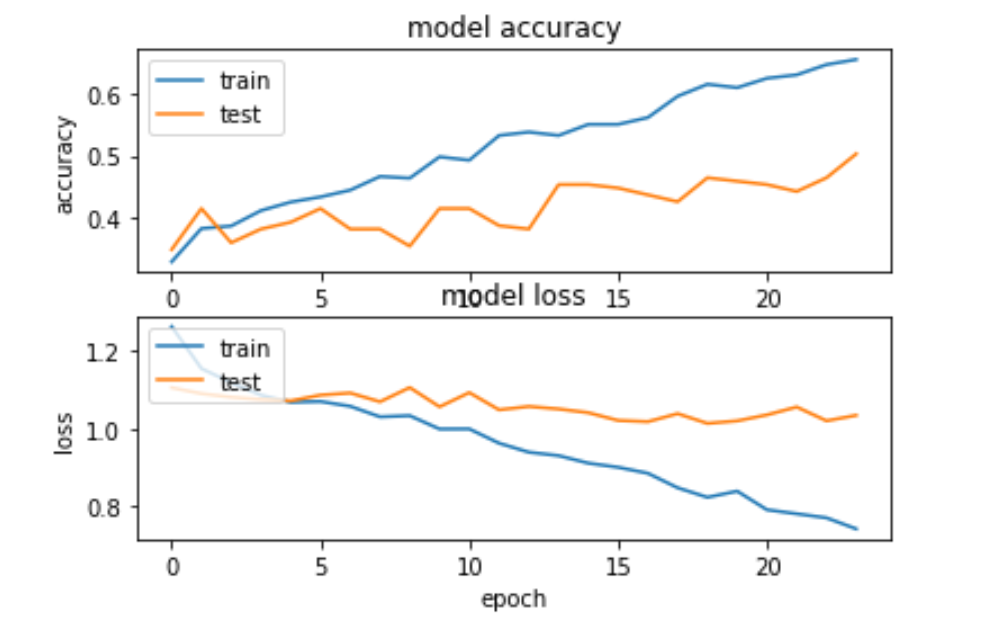
تاریخچه آموزش و آزمایش مدل در زیر آمده است که برای 24 دوره آموزش داده شده است.
مراحل بعدی
این نتیجه اولیه نشان می دهد که مدل های یادگیری عمیق که روی متن در نسخه های درآمد آموزش داده می شوند و منابع دیگر می توانند یک مکانیسم مناسب برای بهبود کیفیت اطلاعات موجود در مورد تصمیمات سرمایه گذاری ، به ویژه در جلوگیری از ضررهای سرمایه گذاری ، اثبات کنند. در حالی که این مدل باید با نمونه های بیشتر ، اصلاح واژگان خاص دامنه و تقویت متن بهبود یابد ، این نشان می دهد که ارائه این سیگنال به عنوان ورودی دیگر تصمیم گیری برای تحلیلگر سرمایه گذاری باعث افزایش کارآیی کار تجزیه و تحلیل شرکت می شود.
شریک زندگی ما به دنبال بهبود مدل با نمونه های بیشتر و تقویت اطلاعات اضافی از انتشار درآمد و نشریات اضافی و نمونه بزرگتر از شرکت ها خواهد بود. آنها همچنین برای درک بهتر ماهیت پی در پی انتشار و اطلاعات عملکرد ، معماری های مدل جایگزین از جمله LSTM را کشف می کنند. علاوه بر این ، آنها به دنبال تکرار این مدل برای صنایع مختلف و عملیاتی کردن مدل با Azure Machine Leaing Workbench هستند و امکان مقیاس خودکار و مدیریت مدل سفارشی را برای بسیاری از مشتریان فراهم می کنند.
به طور کلی ، این نمونه اولیه سرمایه گذاری اضافی توسط شریک زندگی ما در یادگیری عمیق زبان طبیعی را برای بهبود کارآیی ، ثبات و اثربخشی بررسی های انسانی گزارش های متنی و اطلاعات تأیید کرده است. لطفاً در نظرات زیر یا مستقیم از طریق TwitterSingData ، در نظرات زیر یا مستقیم استفاده کنید.
استراتژی ترید...
ما را در سایت استراتژی ترید دنبال می کنید
برچسب :
نویسنده : مرجان شیرمحمدی
بازدید : 39
