- MT5 Pro Set Incl. دیسک های ترمز طوفان HC - نسخه ویژه
- سرمایه گذاری کمی: هزینه معامله و تجزیه و تحلیل لغزش
- مطالعه روش جدید در زمان واقعی را برای شناسایی حباب های سهام مانند GameStop نشان می دهد
- بازار سهام امروز: سهام آسیایی عمدتاً به دلیل نگرانی نسبت به بانک های آمریکایی ، رشد چین کمتر است
- Cryptocurrency News - چگونه می توان لیست های سکه آینده را پیدا کرد؟
- بهترین 7 راه درآمد برای کسب درآمد از اینترنت بدون سرمایه گذاری
- باناریوم محدود
- 7 اصل برنامه ریزی استادانه
- تنظیم کننده سابق شهر می گوید ، هنگ کنگ به عنوان قوانین دارایی دیجیتال برای چین قوانین ماسهبازی برای چین است
- همه سزاوار داروهای ایمن و مقرون به صرفه هستند.

آخرین مطالب
امکانات وب



Filippo Menczer استاد برجسته انفورماتیک و علوم کامپیوتر و مدیر رصدخانه رسانه های اجتماعی در دانشگاه ایندیانا بلومینگتون است. وی در مورد گسترش اطلاعاتی مطالعه می کند و ابزاری را برای مقابله با دستکاری در رسانه های اجتماعی ایجاد می کند. اعتبار: نیک هیگینز

توماس هیلز استاد روانشناسی و مدیر برنامه کارشناسی ارشد رفتاری و داده در دانشگاه وارویک در انگلیس است. تحقیقات وی به تکامل ذهن و اطلاعات می پردازد. اعتبار: نیک هیگینز
نویسندگان
Filippo Menczer استاد برجسته انفورماتیک و علوم کامپیوتر و مدیر رصدخانه رسانه های اجتماعی در دانشگاه ایندیانا بلومینگتون است. وی در مورد گسترش اطلاعاتی مطالعه می کند و ابزاری را برای مقابله با دستکاری در رسانه های اجتماعی ایجاد می کند. اعتبار: نیک هیگینز
توماس هیلز استاد روانشناسی و مدیر برنامه کارشناسی ارشد رفتاری و داده در دانشگاه وارویک در انگلیس است. تحقیقات وی به تکامل ذهن و اطلاعات می پردازد. اعتبار: نیک هیگینز
C Onsider Andy ، که نگران انقباض Covid در سال 2020 است. قادر به خواندن تمام مقالاتی که در مورد آن می بیند ، او برای راهنمایی به دوستان قابل اعتماد اعتماد دارد. وقتی کسی در فیس بوک اظهار داشت که ترس همه گیر از بین می رود ، اندی در ابتدا این ایده را رد می کند. اما پس از آن هتلی که در آن کار می کند درهای خود را می بندد و با کار خود در معرض خطر ، اندی شروع به تعجب می کند که واقعاً تهدید ویروس چقدر جدی است. از همه ، هیچ کس که او می داند درگذشت. یک همکار مقاله ای در مورد "ترس" Covid توسط Big Pharma در تبانی با سیاستمداران فاسد ایجاد کرده است ، که با بی اعتمادی اندی نسبت به دولت روبرو می شود. جستجوی وب وی به سرعت او را به مقالاتی می برد که ادعا می کند Covid بدتر از آنفولانزا نیست. اندی به یک گروه آنلاین از افرادی می پیوندد که از آنجا خارج شده اند یا می ترسند و به زودی خود را می بینند ، مانند بسیاری از آنها ، "چه بیماری همه گیر؟"هنگامی که او می آموزد که چندین نفر از دوستان جدیدش قصد دارند در یک تظاهرات شرکت کنند و خواستار پایان دادن به قفل شدن باشند ، وی تصمیم می گیرد به آنها بپیوندد. تقریباً هیچ کس در اعتراض گسترده ، از جمله او ، ماسک نمی پوشد. هنگامی که خواهرش در مورد این تظاهرات سؤال می کند ، اندی محکومیتی را که اکنون بخشی از هویت او شده است به اشتراک می گذارد: Covid یک فریب است.
این مثال میدان مین سوگیری های شناختی را نشان می دهد. ما اطلاعات را از افرادی که به آنها اعتماد داریم، در گروه خود ترجیح می دهیم. ما به خطرات - برای اندی، خطر از دست دادن شغلش - توجه می کنیم و به احتمال زیاد اطلاعاتی درباره آن به اشتراک می گذاریم. ما چیزهایی را جست وجو می کنیم و به خاطر می آوریم که به خوبی با آنچه قبلاً می دانیم و درک می کنیم مطابقت دارد. این سوگیری ها محصول گذشته تکاملی ما هستند و برای ده ها هزار سال به خوبی به ما خدمت کرده اند. افرادی که مطابق با آنها رفتار می کردند - به عنوان مثال، با دور ماندن از حوضچه بیش از حد رشد کرده که در آن شخصی گفته بود افعی وجود دارد - احتمال زنده ماندن آنها بیشتر از کسانی بود که این کار را نمی کردند.
با این حال، فناوری های مدرن این سوگیری ها را به روش های مضر تقویت می کنند. موتورهای جستجو، اندی را به سایت هایی هدایت می کنند که سوء ظن او را برمی انگیزد و رسانه های اجتماعی او را با افراد همفکرش مرتبط می کنند و ترس های او را تغذیه می کنند. بدتر شدن اوضاع، ربات ها - حساب های خودکار رسانه های اجتماعی که خود را شبیه انسان ها می کنند - به بازیگران گمراه یا بدخواه این امکان را می دهند که از آسیب پذیری های او استفاده کنند.
تشدید مشکل، گسترش اطلاعات آنلاین است. مشاهده و تولید وبلاگ ها، ویدئوها، توییت ها و سایر واحدهای اطلاعاتی به نام میم به قدری ارزان و آسان شده است که بازار اطلاعات را غرق کرده است. ناتوان از پردازش همه این مطالب، به سوگیری های شناختی خود اجازه می دهیم تصمیم بگیرند که به چه چیزی توجه کنیم. این میانبرهای ذهنی تا حد مضری بر اطلاعاتی که جستجو، درک، به خاطر سپردن و تکرار می کنیم تأثیر می گذارد.
نیاز به درک این آسیب پذیری های شناختی و نحوه استفاده یا دستکاری الگوریتم ها از آنها ضروری شده است. در دانشگاه وارویک در انگلستان و رصدخانه بلومینگتون در دانشگاه ایندیانا در رسانه های اجتماعی (OSoMe، با تلفظ عالی)، تیم های ما از آزمایش های شناختی، شبیه سازی، داده کاوی و هوش مصنوعی برای درک آسیب پذیری های شناختی کاربران رسانه های اجتماعی استفاده می کنند. بینش های حاصل از مطالعات روان شناختی در مورد تکامل اطلاعات انجام شده در وارویک، مدل های کامپیوتری توسعه یافته در ایندیانا را نشان می دهد و بالعکس. ما همچنین در حال توسعه ابزارهای کمکی تحلیلی و یادگیری ماشینی برای مبارزه با دستکاری رسانه های اجتماعی هستیم. برخی از این ابزارها قبلاً توسط روزنامه نگاران، سازمان های جامعه مدنی و افراد برای شناسایی بازیگران غیر معتبر، ترسیم گسترش روایت های نادرست و تقویت سواد خبری استفاده می شوند.
اضافه بار اطلاعات
انبوه اطلاعات رقابت شدیدی را برای جلب توجه مردم ایجاد کرده است. همانطور که هربرت آ. سیمون، اقتصاددان و روانشناس برنده جایزه نوبل، خاطرنشان کرد: «آنچه اطلاعات مصرف می کند کاملاً واضح است: توجه گیرندگان خود را به خود جلب می کند». یکی از اولین پیامدهای به اصطلاح اقتصاد توجه، از دست دادن اطلاعات با کیفیت بالا است. تیم OSoMe این نتیجه را با مجموعه ای از شبیه سازی های ساده نشان داد. کاربران رسانه های اجتماعی مانند اندی را که عامل نامیده می شوند، به عنوان گره هایی در شبکه ای از آشنایان آنلاین نشان می داد. در هر مرحله زمانی در شبیه سازی، عوامل ممکن است یک الگوی رفتاری ایجاد کنند یا آن را دوباره به اشتراک بگذارند که در فید خبری می بینند. برای تقلید از توجه محدود، نمایندگان مجاز هستند فقط تعداد معینی از موارد را در بالای فیدهای خبری خود مشاهده کنند.
با اجرای این شبیه سازی در چندین مرحله زمانی، لیلیان ونگ، اکنون در OpenAI، و محققان OSoMe دریافتند که با محدود شدن توجه عوامل، انتشار میم ها منعکس کننده توزیع قانون قدرت رسانه های اجتماعی واقعی است: احتمال اینکهمیم به تعداد معینی به اشتراک گذاشته می شد که تقریباً توان معکوس آن عدد بود. برای مثال، احتمال اینکه یک میم سه بار به اشتراک گذاشته شود تقریباً نه برابر کمتر از یک بار اشتراک گذاری آن بود.
این الگوی محبوبیت برنده همه چیز از میم ها، که در آن اکثر آنها به سختی مورد توجه قرار می گیرند در حالی که تعداد کمی از آنها به طور گسترده پخش می شوند، نمی توان با جذاب تر یا به نوعی ارزشمندتر بودن برخی از آنها توضیح داد: میم ها در این دنیای شبیه سازی شده هیچ کیفیت ذاتی ندارند. ویروسی بودن صرفاً از پیامدهای آماری تکثیر اطلاعات در یک شبکه اجتماعی از عوامل با توجه محدود ناشی می شود. حتی زمانی که نمایندگان ترجیحا میم های با کیفیت بالاتر را به اشتراک می گذاشتند، محقق Xiaoyan Qiu که در آن زمان در OSoMe بود، بهبود کمی را در کیفیت کلی کسانی که بیشتر به اشتراک گذاشته بودند مشاهده کرد. مدل های ما نشان دادند که حتی زمانی که می خواهیم اطلاعات باکیفیت را ببینیم و به اشتراک بگذاریم، ناتوانی ما در مشاهده همه چیز در فیدهای خبری مان ناگزیر ما را به اشتراک گذاری چیزهایی سوق می دهد که تا حدی یا کاملاً نادرست است.
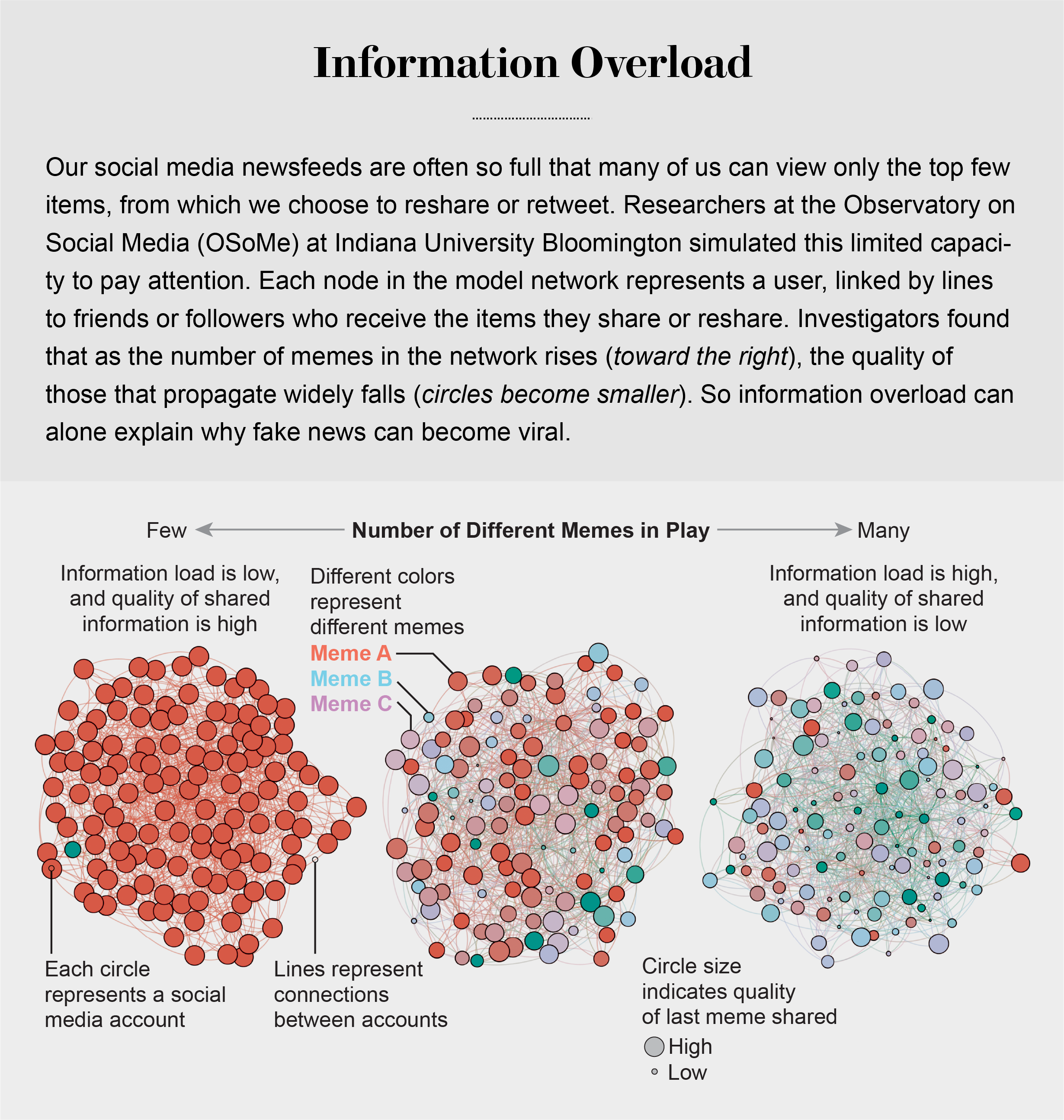
منبع: «توجه محدود فردی و ویروسی بودن آنلاین اطلاعات با کیفیت پایین»، توسط Xiaoyan Qiu و همکاران، در Nature Human Behavior، جلد. 1 ژوئن 2017
تعصبات شناختی مشکل را بسیار بدتر می کند. در مجموعه ای از مطالعات پیشگامانه در سال 1932 ، روانشناس فردریک بارتلت به داوطلبان افسانه بومی آمریکا در مورد جوانی که می شنود گریه های جنگ و با تعقیب آنها ، وارد یک نبرد رویایی می شود که در نهایت منجر به مرگ واقعی وی می شود. بارتلت از داوطلبان ، که غیر بومی بودند ، خواسته است تا داستان نسبتاً گیج کننده را در فواصل افزایش ، از دقایقی تا سالها بعد به یاد بیاورند. وی دریافت که با گذشت زمان ، یادآوری ها تمایل داشتند قسمت های ناآشنا این داستان را تحریف کنند به گونه ای که یا به حافظه گم شده اند یا به چیزهای آشناتری تبدیل شده اند. اکنون می دانیم که ذهن ما این کار را همیشه انجام می دهد: آنها درک ما از اطلاعات جدید را تنظیم می کنند تا با آنچه ما می دانیم متناسب باشد. یکی از پیامدهای این تعصب به اصطلاح تأیید این است که افراد غالباً به دنبال اطلاعات هستند ، به یاد می آورند و می توانند اطلاعاتی را که به بهترین وجه آنچه را که قبلاً معتقدند تأیید می کند ، به یاد بیاورند و درک کنند.
این گرایش بسیار دشوار است. آزمایشات به طور مداوم نشان می دهد که حتی وقتی افراد با اطلاعات متعادل حاوی دیدگاه هایی از دیدگاه های مختلف روبرو می شوند ، تمایل دارند شواهد حمایتی را برای آنچه قبلاً معتقدند پیدا کنند. و هنگامی که افراد دارای اعتقادات واگرا در مورد موضوعات عاطفی از نظر عاطفی مانند تغییر آب و هوا ، اطلاعات مشابهی در مورد این مباحث نشان داده می شوند ، آنها حتی بیشتر به مواضع اصلی خود متعهد می شوند.
بدتر شدن امور ، موتورهای جستجو و سیستم عامل های رسانه های اجتماعی توصیه های شخصی را بر اساس مقادیر زیادی از داده های موجود در مورد ترجیحات گذشته کاربران ارائه می دهند. آنها اطلاعات را در فیدهای ما در اولویت قرار می دهند که ما به احتمال زیاد با آنها موافق هستیم - مهم نیست که چقدر حاشیه است - و ما را از اطلاعاتی که ممکن است ذهن ما را تغییر دهد ، محافظت می کنیم. این باعث می شود اهداف آسان برای قطبش باشیم. NIR GRINBERG و همکارانش در دانشگاه شمال شرقی در سال 2019 نشان دادند که محافظه کاران در ایالات متحده آمریكا بیشتر از اطلاعات نادرست پذیرفته می شوند. اما تجزیه و تحلیل خود ما از مصرف اطلاعات با کیفیت پایین در توییتر نشان می دهد که آسیب پذیری در هر دو طرف طیف سیاسی اعمال می شود و هیچ کس نمی تواند به طور کامل از آن جلوگیری کند. حتی توانایی ما در تشخیص دستکاری آنلاین تحت تأثیر تعصب سیاسی ما قرار می گیرد ، هرچند که متقارن نیست: کاربران جمهوریخواه به احتمال زیاد ربات هایی را برای ترویج ایده های محافظه کارانه برای انسان اشتباه می کنند ، در حالی که دموکرات ها بیشتر به احتمال زیاد کاربران محافظه کار انسانی را برای رباتها اشتباه می کنند.
گله اجتماعی
در شهر نیویورک در آگوست سال 2019 ، مردم شروع به فرار از آنچه به نظر می رسید مانند شلیک گلوله است. دیگران دنبال کردند ، برخی فریاد زدند ، "تیرانداز!"فقط بعداً آنها یاد گرفتند که این انفجارها از یک موتور سیکلت عقب نشینی ناشی شده است. در چنین شرایطی ، ممکن است هزینه اول را بپردازد و بعداً سؤال کند. در صورت عدم وجود سیگنال های روشن ، مغز ما از اطلاعاتی در مورد جمعیت برای استنباط اقدامات مناسب ، مشابه رفتار آموزش ماهی و پرندگان گله استفاده می کند.
چنین انطباق اجتماعی فراگیر است. در یک مطالعه جذاب در سال 2006 که شامل 14000 داوطلب وب مستقر در وب ، متیو سالگانیک ، سپس در دانشگاه کلمبیا است و همکارانش دریافتند که وقتی افراد می توانند موسیقی دیگران را بارگیری کنند ، آنها را بارگیری می کنند. علاوه بر این ، هنگامی که مردم در گروه های "اجتماعی" جدا می شدند ، که در آن می توانستند ترجیحات دیگران را در حلقه خود ببینند اما هیچ اطلاعاتی در مورد افراد خارجی نداشتند ، انتخاب گروه های انفرادی به سرعت واگرا شد. اما ترجیحات گروههای "غیر اجتماعی" ، جایی که هیچ کس از انتخاب دیگران نمی دانست ، نسبتاً پایدار ماند. به عبارت دیگر ، گروه های اجتماعی فشار به سمت انطباق آنقدر قدرتمند ایجاد می کنند که می تواند بر ترجیحات فردی غلبه کند و با تقویت اختلافات اولیه تصادفی ، می تواند باعث شود گروه های جداگانه به افراط و تفریط واگرایی کنند.
رسانه های اجتماعی از پویایی مشابهی پیروی می کنند. ما محبوبیت را با کیفیت اشتباه می گیریم و در نهایت کپی کردن از رفتاری که مشاهده می کنیم. آزمایشات در توییتر توسط Bjarke Mønsted ، سپس در دانشگاه فنی دانمارک ، و همکارانش نشان می دهند که اطلاعات از طریق "مسری پیچیده" منتقل می شوند: هنگامی که ما به طور مکرر در معرض یک ایده قرار می گیریم ، به طور معمول از بسیاری از منابع ، ما به احتمال زیاد پذیرفته می شویم و به احتمال زیاد می توانیم تصویب کنیم ودوباره آن را تغییر دهید. این تعصب اجتماعی بیشتر توسط آنچه روانشناسان آن را "تأثیر قرار گرفتن در معرض" می نامند تقویت می شود: هنگامی که مردم بارها در معرض همان محرک ها قرار می گیرند ، مانند چهره های خاص ، آنها رشد می کنند تا آن محرک ها را بیشتر از آنهایی که با آنها کمتر دیده می شوند ، دوست داشته باشند.
چنین تعصبات به یک اصرار غیر قابل مقاومت برای توجه به اطلاعاتی که ویروسی می شود تبدیل می شود - اگر همه افراد در مورد آن صحبت می کنند ، باید مهم باشد. علاوه بر نشان دادن مواردی که با دیدگاه های ما مطابقت دارد ، سیستم عامل های رسانه های اجتماعی مانند فیس بوک ، توییتر ، یوتیوب و اینستاگرام محتوای محبوب را در بالای صفحه های ما قرار می دهند و به ما نشان می دهند که چند نفر چیزی را دوست داشته و به اشتراک گذاشته اند. تعداد کمی از مردم متوجه می شوند که این نشانه ها ارزیابی مستقل از کیفیت را ارائه نمی دهند.
در حقیقت ، برنامه نویسان که الگوریتم هایی را برای رتبه بندی Memes در رسانه های اجتماعی طراحی می کنند ، فرض می کنند که "خرد جمعیت" به سرعت موارد با کیفیت بالا را شناسایی می کند. آنها از محبوبیت به عنوان یک پروکسی برای کیفیت استفاده می کنند. تجزیه و تحلیل ما از مقادیر زیادی از داده های ناشناس در مورد کلیک نشان می دهد که همه سیستم عامل ها - رسانه های اجتماعی ، موتورهای جستجو و سایت های خبری - به طور کلی اطلاعاتی را از زیر مجموعه باریک از منابع محبوب ارائه می دهند.
برای درک دلیل ، ما الگوبرداری کردیم که چگونه آنها سیگنال ها را برای کیفیت و محبوبیت در رتبه بندی خود ترکیب می کنند. در این مدل ، مأمورین با توجه محدود - کسانی که فقط تعداد معینی از موارد را در صدر فیدهای خبری خود می بینند - همچنین به احتمال زیاد روی الگوی رفتاری که توسط این سکو بالاتر هستند ، کلیک می کنند. هر مورد از کیفیت ذاتی و همچنین سطح محبوبیت تعیین شده توسط چند بار روی آن کلیک می کند. متغیر دیگر میزان متکی به رتبه بندی به محبوبیت و نه کیفیت را ردیابی می کند. شبیه سازی این مدل نشان می دهد که چنین تعصب الگوریتمی به طور معمول باعث سرکوب کیفیت الگوهای رفتاری حتی در صورت عدم تعصب انسانی می شود. حتی وقتی می خواهیم بهترین اطلاعات را به اشتراک بگذاریم ، الگوریتم ها در نهایت ما را گمراه می کنند.
اتاق های اکو
بیشتر ما اعتقاد نداریم که گله را دنبال می کنیم. اما تعصب تأیید ما باعث می شود تا دیگران را مانند ما دنبال کنیم ، پویایی که گاهی اوقات به عنوان هموفیش خوانده می شود-تمایل به افراد همفکر برای ارتباط با یکدیگر. رسانه های اجتماعی با اجازه دادن به کاربران برای تغییر ساختارهای شبکه اجتماعی خود از طریق دنبال کردن ، عدم دوست داشتن و غیره ، به صورت هموفیلی تقویت می کنند. نتیجه این است که مردم در جوامع بزرگ ، متراکم و به طور فزاینده ای که معمولاً به عنوان اتاق های اکو توصیف می شوند ، جدا می شوند.
در اوسوم ، ما ظهور اتاق های اکو آنلاین را از طریق شبیه سازی دیگری به نام Echodemo بررسی کردیم. در این مدل ، هر نماینده دارای یک عقیده سیاسی است که توسط تعدادی از 1 ((مثلاً لیبرال) تا 1 (محافظه کار) نشان داده شده است. این تمایلات در پست های نمایندگان منعکس می شود. مأمورین همچنین تحت تأثیر عقایدی هستند که در فیدهای خبری خود می بینند و می توانند کاربران را با عقاید متفاوت از بین ببرند. با شروع شبکه ها و عقاید اولیه تصادفی ، دریافتیم که ترکیب تأثیر اجتماعی و ناآرامی ، شکل گیری جوامع قطبی و تفکیک شده را بسیار تسریع می کند.
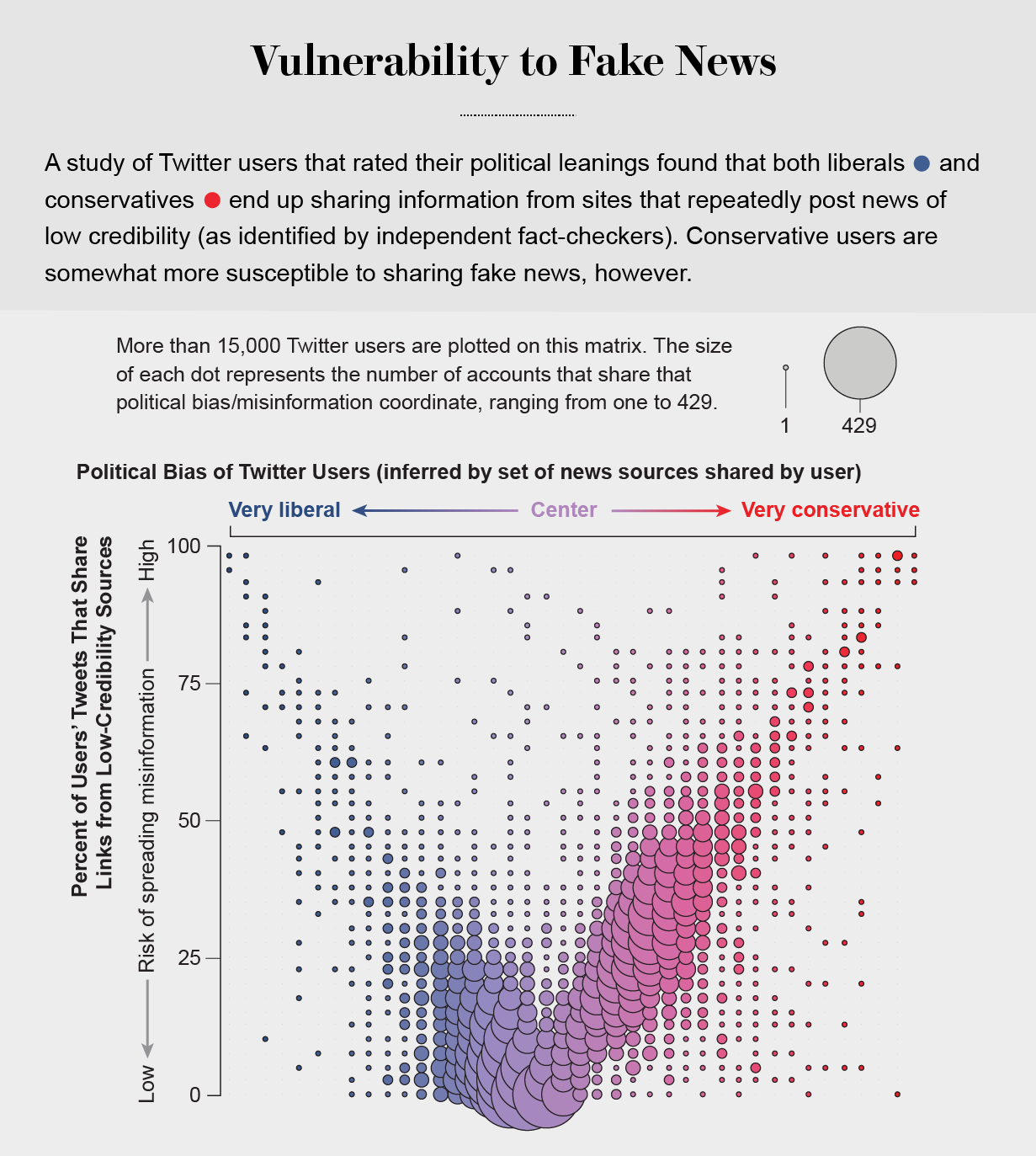
در واقع ، اتاق های اکو سیاسی در توییتر به حدی شدید هستند که می توان تمایلات سیاسی کاربران را با دقت بالایی پیش بینی کرد: شما همان عقاید را با اکثر ارتباطات خود دارید. این ساختار مجلل به طور مؤثر اطلاعات را در یک جامعه پخش می کند در حالی که آن جامعه را از گروه های دیگر عایق می کند. در سال 2014 ، گروه تحقیقاتی ما توسط یک کمپین اطلاعاتی از کارآزمایی هدف قرار گرفت و ادعا کرد که ما بخشی از یک تلاش با انگیزه سیاسی برای سرکوب گفتار آزاد بودیم. این اتهام دروغین عمدتاً در اتاق اکو محافظه کارانه گسترش یافته است ، در حالی که مقالاتی که توسط افراد چکیده حقایق را از بین می برد ، عمدتاً در جامعه لیبرال یافت می شد. متأسفانه ، چنین تفکیک اخبار جعلی از گزارش های بررسی حقایق آنها عادی است.
رسانه های اجتماعی همچنین می توانند منفی را افزایش دهند. در یک مطالعه آزمایشگاهی سال 2018 ، رابرت جاگیلو ، اکنون در دانشگاه آکسفورد ، و یکی از ما (هیلز) دریافتند که اطلاعات مشترک اجتماعی نه تنها تعصبات را تقویت می کند بلکه در برابر تصحیح نیز مقاوم تر می شود. ما بررسی کردیم که چگونه اطلاعات از شخص به شخص دیگر در یک زنجیره به اصطلاح انتشار اجتماعی منتقل می شود. در این آزمایش ، اولین نفر در این زنجیره مجموعه ای از مقالات مربوط به انرژی هسته ای یا مواد افزودنی غذایی را خواند. این مقالات به صورت متعادل طراحی شده اند ، حاوی اطلاعات مثبت (به عنوان مثال ، در مورد آلودگی کمتر کربن یا مواد غذایی طولانی تر) به عنوان اطلاعات منفی (مانند خطر ذوب شدن یا آسیب احتمالی به سلامتی).
اولین نفر در زنجیره انتشار اجتماعی در مورد مقاله به شخص بعدی گفت ، دوم به سوم و غیره گفت. ما افزایش کلی در میزان اطلاعات منفی را مشاهده کردیم زیرا در طول زنجیره عبور می کند - که به عنوان تقویت اجتماعی خطر شناخته شده است. علاوه بر این ، کار دانیل جی ناوارو و همکارانش در دانشگاه نیو ساوت ولز در استرالیا دریافتند که اطلاعات در زنجیره های انتشار اجتماعی بیشترین حساسیت توسط افراد با شدیدترین تعصب را دارد.
حتی بدتر از آن ، انتشار اجتماعی همچنین باعث می شود که اطلاعات منفی "چسبنده" تر شود. هنگامی که Jagiello و Hills متعاقباً مردم را در زنجیره های انتشار اجتماعی به اطلاعات اصلی و متعادل در معرض دید قرار دادند - یعنی خبرهایی که اولین شخص در این زنجیره دیده بود - اطلاعات متعادل برای کاهش نگرش منفی افراد کمی انجام نمی داد. اطلاعاتی که از طریق مردم گذشت ، نه تنها منفی تر شده بود بلکه در برابر به روزرسانی نیز مقاوم تر بود.
یک مطالعه سال 2015 توسط Emilio Ferrara و Zeyao Yang ، سپس هر دو محقق Osome ، داده های تجربی در مورد چنین "مسری عاطفی" را در توییتر مورد تجزیه و تحلیل قرار دادند و دریافتند که افراد بیش از حد از محتوای منفی تمایل به اشتراک پست های منفی دارند ، در حالی که افراد بیش از حد به محتوای مثبت تمایل دارند که بیشتر به اشتراک بگذارندپست های مثبتاز آنجا که محتوای منفی سریعتر از محتوای مثبت گسترش می یابد ، با ایجاد روایاتی که باعث ایجاد پاسخ های منفی مانند ترس و اضطراب می شود ، می توان احساسات را دستکاری کرد. فرارا ، هم اکنون در دانشگاه کالیفرنیای جنوبی ، و همکارانش در بنیاد برونو کسلر در ایتالیا نشان داده اند که در طی همه پرسی اسپانیا در استقلال کاتالونیا ، ربات های اجتماعی برای بازتوییت روایت های خشونت آمیز و التهابی ، افزایش قرار گرفتند و در معرض دید خود قرار دادند و درگیری های اجتماعی را تشدید کردند.
ظهور رباتها
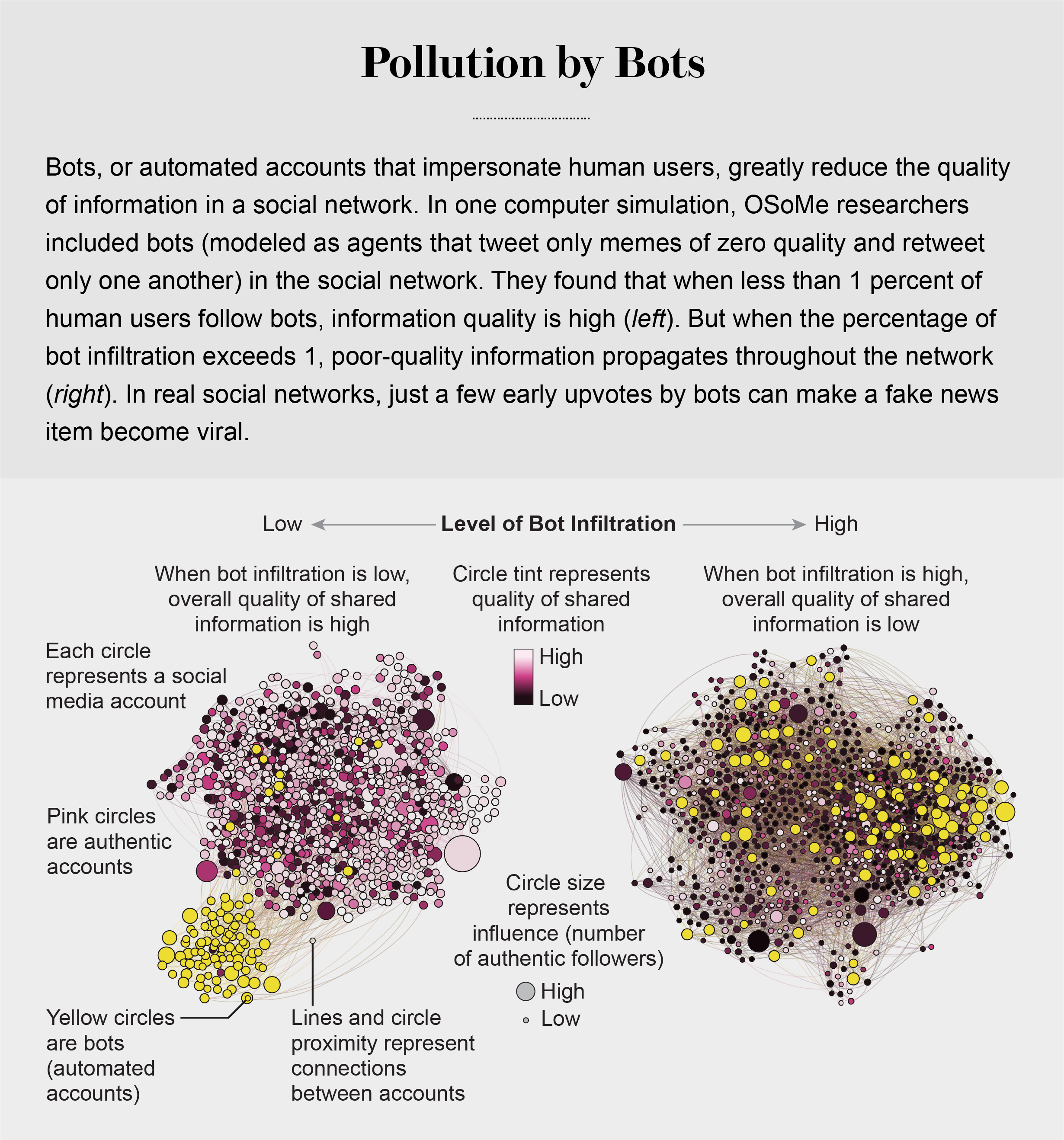
کیفیت اطلاعات بیشتر توسط ربات های اجتماعی مختل می شود ، که می تواند از همه نقاط ضعف شناختی ما سوء استفاده کند. ایجاد رباتها آسان است. سیستم عامل های رسانه های اجتماعی رابط های برنامه نویسی به اصطلاح برنامه را ارائه می دهند که باعث می شود یک بازیگر واحد بتواند هزاران ربات را تنظیم و کنترل کند. اما تقویت یک پیام ، حتی با وجود چند رعایت اولیه توسط رباتها در سیستم عامل های رسانه های اجتماعی مانند Reddit ، می تواند تأثیر زیادی در محبوبیت بعدی یک پست بگذارد.
در Osome ، ما الگوریتم های یادگیری ماشین را برای شناسایی ربات های اجتماعی ایجاد کرده ایم. یکی از این ، بوتومتر ، ابزاری عمومی است که 1200 ویژگی را از یک حساب توییتر خاص برای توصیف مشخصات آن ، دوستان ، ساختار شبکه اجتماعی ، الگوهای فعالیت زمانی ، زبان و سایر ویژگی ها استخراج می کند. این برنامه این خصوصیات را با ده ها هزار ربات که قبلاً شناسایی شده بودند مقایسه می کند تا به حساب توییتر برای استفاده احتمالی خود از اتوماسیون امتیاز بدهد.
در سال 2017 ما تخمین زدیم که حداکثر 15 درصد از حساب های فعال توییتر ربات ها بودند - و آنها نقش اساسی در گسترش اطلاعات غلط در دوره انتخابات ایالات متحده 2016 داشتند. در عرض چند ثانیه از یک مقاله خبری جعلی که در حال ارسال است - مانند یکی از ادعای کمپین کلینتون در آیین های غیبی - توسط بسیاری از ربات ها توییت می شود ، و انسان ها ، که از محبوبیت ظاهری محتوا استفاده می شود ، آن را بازتوییت می کند.
رباتها همچنین با تظاهر به نمایندگی از افرادی از گروه ما ، ما را تحت تأثیر قرار می دهند. یک ربات فقط باید دنبال کند ، کسی را در یک جامعه آنلاین بازخوانی و بازخوانی کنید تا به سرعت در آن نفوذ کند. شیاودان لو از دانشگاه عادی پکن ، که با اوسوم کار می کند ، الگوی دیگری را تهیه کرد که در آن برخی از عوامل ربات هایی هستند که به یک شبکه اجتماعی نفوذ می کنند و محتوای فریبنده با کیفیت پایین را به اشتراک می گذارند-فکر می کنند ClickBait. یک پارامتر در مدل این احتمال را توصیف می کند که یک عامل معتبر از رباتها پیروی کند - که برای اهداف این مدل ، ما به عنوان عواملی تعریف می کنیم که ممتاز با کیفیت صفر تولید می کنند و فقط یکدیگر را بازتوییت می کنند. شبیه سازی های ما نشان می دهد که این ربات ها می توانند با نفوذ به بخش کوچکی از شبکه ، کل کیفیت اطلاعات اکوسیستم را سرکوب کنند. رباتها همچنین می توانند با پیشنهاد سایر حسابهای غیر معتبری که باید دنبال شوند ، شکل گیری اتاق های اکو را تسریع کنند ، تکنیکی که به عنوان ایجاد "قطار دنبال می شود".
برخی از دست سازها هر دو طرف تقسیم را از طریق سایت های خبری جعلی و رباتها ، هدایت قطبش سیاسی یا کسب درآمد توسط تبلیغات بازی می کنند. در اوسوم ، ما شبکه ای از حساب های غیر معتبر را در توییتر کشف کردیم که همگی توسط یک نهاد مشابه هماهنگ شده بودند. برخی وانمود می کنند که هواداران طرفدار ترامپ در انتخابات انتخاباتی ایالات متحده آمریکا دوباره بزرگ هستند ، در حالی که برخی دیگر به عنوان ترامپ "مقاومت" می کردند و همه خواستار کمکهای سیاسی شدند. چنین عملیاتی محتوا را تقویت می کند که بر تعصبات تأیید می شود و شکل گیری اتاق های اکو قطبی را تسریع می کند.
مهار دستکاری آنلاین
درک تعصبات شناختی ما و چگونگی سوء استفاده از الگوریتم ها و رباتها از آنها به ما امکان می دهد تا در برابر دستکاری بهتر محافظت کنیم. اوسوم چندین ابزار برای کمک به مردم در درک آسیب پذیری های خود و همچنین نقاط ضعف سیستم عامل های رسانه های اجتماعی تولید کرده است. یکی از برنامه های تلفن همراه به نام Fakey است که به کاربران کمک می کند تا نحوه مشاهده اطلاعات نادرست را یاد بگیرند. این بازی یک فید اخبار رسانه های اجتماعی را شبیه سازی می کند و مقالات واقعی از منابع با اعتبار کم و بالا را نشان می دهد. کاربران باید تصمیم بگیرند که چه چیزی می توانند یا نباید به اشتراک بگذارند و چه چیزی را بررسی کنند. تجزیه و تحلیل داده های Fakey شیوع گله های اجتماعی آنلاین را تأیید می کند: کاربران وقتی معتقدند که بسیاری از افراد دیگر آنها را به اشتراک گذاشته اند ، احتمالاً مقالات کم اعتبار را به اشتراک می گذارند.
برنامه دیگری که در دسترس عموم قرار دارد ، به نام Hoxy ، نشان می دهد که چگونه هرگونه الگوی رفتاری موجود از طریق توییتر گسترش می یابد. در این تجسم ، گره ها حساب های واقعی توییتر را نشان می دهند ، و پیوندها نشان می دهد که چگونه بازتوییت ، نقل قول ها ، ذکر ها و پاسخ ها باعث می شود که این یادداشت را از حساب به حساب دیگر پخش کند. هر گره دارای رنگی است که نمره خود را از بوتومتر نشان می دهد ، که به کاربران امکان می دهد مقیاس را مشاهده کنند که در آن ربات ها اطلاعات غلط را تقویت می کنند. این ابزارها توسط روزنامه نگاران تحقیقاتی برای کشف ریشه های کمپین های اطلاعات نادرست مورد استفاده قرار گرفته است ، مانند کسی که توطئه "پیتزاگات" را در ایالات متحده تحت فشار قرار می دهد. با این حال ، با توجه به اینکه الگوریتم های یادگیری ماشین در تقلید از رفتار انسان بهتر می شوند ، دستکاری سخت تر می شود.
جدا از پخش اخبار جعلی ، کمپین های اطلاعات نادرست همچنین می توانند توجه سایر مشکلات جدی تر را منحرف کنند. برای مقابله با چنین دستکاری ، ما یک ابزار نرم افزاری به نام Botslayer ایجاد کردیم. این هشتگ ، پیوندها ، حساب ها و سایر ویژگی هایی را که در توییت در مورد موضوعاتی که کاربر می خواهد مطالعه کند ، استخراج می کند. برای هر نهاد ، Botslayer توییت ها را ردیابی می کند ، حساب هایی که آنها را ارسال می کنند و نمرات ربات های آنها را به اشخاص پرچم که گرایش دارند و احتمالاً توسط رباتها یا حسابهای هماهنگ تقویت می شوند. هدف این است که خبرنگاران ، سازمان های جامعه مدنی و نامزدهای سیاسی را قادر به مشاهده و پیگیری کمپین های تأثیرگذار در زمان واقعی کنند.
این ابزارهای برنامه ای کمکهای مهمی هستند ، اما تغییرات نهادی نیز برای مهار گسترش اخبار جعلی ضروری است. آموزش می تواند کمک کند ، اگرچه بعید است همه مباحثی را که افراد گمراه شده اند ، شامل شود. برخی از دولت ها و سیستم عامل های رسانه های اجتماعی نیز در تلاشند تا دستکاری آنلاین و اخبار جعلی را کاهش دهند. اما چه کسی تصمیم می گیرد که جعلی یا دستکاری کننده چیست و چه چیزی نیست؟اطلاعات می توانند با برچسب های هشدار دهنده مانند مواردی که فیس بوک و توییتر ارائه می دهند ، ارائه شود ، اما آیا به افرادی که از آن برچسب ها استفاده می کنند می توانند اعتماد کنند؟این خطر که چنین اقداماتی می تواند به طور عمدی یا سهواً سرکوب گفتار آزاد ، که برای دموکراسی های قوی بسیار مهم است ، واقعی باشد. تسلط بر بسترهای رسانه های اجتماعی با دسترسی جهانی و روابط نزدیک با دولت ها ، امکانات را بیشتر پیچیده می کند.
یکی از بهترین ایده ها ممکن است ایجاد و به اشتراک گذاری اطلاعات کم کیفیت باشد. این می تواند شامل اضافه کردن اصطکاک با مجبور کردن مردم به پرداخت به اشتراک گذاری یا دریافت اطلاعات باشد. پرداخت می تواند به صورت زمان ، کار ذهنی مانند معماها یا هزینه های میکروسکوپی برای اشتراک یا استفاده باشد. ارسال خودکار باید مانند تبلیغات رفتار شود. برخی از سیستم عامل ها در حال حاضر از اصطکاک در قالب Captchas و تأیید تلفن برای دسترسی به حساب ها استفاده می کنند. توییتر محدودیت هایی را در ارسال خودکار قرار داده است. این تلاش ها می تواند گسترش یابد تا به تدریج مشوق های اشتراک آنلاین را به سمت اطلاعاتی که برای مصرف کنندگان ارزشمند است تغییر دهید.
ارتباط رایگان رایگان نیست. با کاهش هزینه اطلاعات ، ارزش آن را کاهش داده ایم و زناشویی آن را دعوت کرده ایم. برای بازگرداندن سلامت اکوسیستم اطلاعاتی ، ما باید آسیب پذیری های ذهن غرق شده خود را درک کنیم و چگونه می توان از اقتصاد اطلاعات استفاده کرد تا از ما در برابر گمراهی محافظت کند.

این مقاله در ابتدا با عنوان "اقتصاد توجه" در علمی آمریکایی 323 ، 6 ، 54-61 (دسامبر 2020) منتشر شد
استراتژی ترید...
ما را در سایت استراتژی ترید دنبال می کنید
برچسب :
نویسنده : مرجان شیرمحمدی
بازدید : 38
